论文日报 | 2026-03-07
📊 今日概览
今日从 arXiv 检索到与研究兴趣相关的最新论文 20 篇,涵盖研究方向:Video Generation、Portrait Video Generation、3D Head Avatar Reconstruction、3D Generation / Morphing、3D Human Avatar Reconstruction 等。
🔬 精选论文深度解析(Top 5)
#01 FaceCam: Portrait Video Camera Control via Scale-Aware Conditioning
⭐ 推荐 | 评分:
8.0/10| 领域:Portrait Video Generation | arXiv · PDF
作者:Weijie Lyu, Ming-Hsuan Yang, Zhixin Shu标签:
Camera Control·Video Diffusion·Portrait Video·Scale-Aware Conditioning·Mixture-of-Experts一句话总结:FaceCam提出一种人脸尺度感知的相机轨迹表示方案,结合合成相机运动与多镜头拼接两种数据策略,实现对单目人像视频的精准相机控制生成。
1. 研究背景与动机
- 研究背景:基于大型视频生成模型(如Wan2.2 MoE扩散模型)的相机控制方法已取得显著进展,但在处理人像视频时往往存在几何畸变和视觉伪影。根本原因在于:现有方法使用尺度模糊(scale-ambiguous)的相机表示(如世界坐标系下的相对位姿),或依赖3D重建(如NeRF/3DGS)引入估计误差;此外,现有数据集中训练相机通常是静态的,难以泛化到动态连续的相机轨迹推理场景。
- 研究问题:如何在不依赖3D先验或复杂3D重建的前提下,为单目人像视频设计一种确定性的(deterministic)相机条件表示,并从静态训练相机数据中学习到动态相机轨迹的生成能力?
- 研究动机:人像视频是相机控制视频生成的核心应用场景(如虚拟直播、影视后期),但人脸的近景特性导致现有通用相机控制方法产生明显的几何失真。一个专门针对人像视频、鲁棒且可确定条件化的相机表示,将显著提升相机可控性和视觉质量,在工业和娱乐领域具有重要价值。
2. 研究任务与图示
图注:FaceCam teaser: portrait video camera control results
3. 研究方法与核心架构
核心方法:FaceCam的核心由三部分组成:
- 面部定制尺度感知相机表示:利用MediaPipe Face Mesh在源视频每帧上检测468个2D/3D面部关键点,将相机变换编码为「关键点图像坐标的映射变化」,无需估计绝对深度或世界坐标,消除了尺度歧义。该表示直接作为视频生成模型的条件信号注入,不携带身份或表情信息。
- 训练数据生成策略:(a) 合成相机运动(Synthetic Camera Motion):对NeRSemble多视角人像视频施加缩放(zoom)和平移(pan)变换,生成时序平滑的连续相机轨迹;(b) 多镜头拼接(Multi-shot Stitching):将多个相机角度的视频片段拼接,引入离散相机角度变化,教会模型适应视角跳变;两者结合并补充野生单目视频提升泛化性。
- 视频生成主干:基于Wan2.2(Mixture-of-Experts视频扩散模型),使用Conditional Flow Matching(CFM)框架,以源视频帧和关键点条件图为输入,生成分辨率704×480、长度81帧的目标视频。
图注:Training and inference pipeline of .
4. 实验结果
- 实验设置:在Ava-256多视角人像数据集上评估,选取10个身份各10对源-目标相机组合(共100段视频)。分两个设置:(1)静态相机设置(29帧);(2)动态相机设置(49帧)。基线方法包括TrajectoryCrafter和ReCamMaster。评估指标涵盖相机可控性、视觉质量、身份保持、运动保持等。此外在多样野生视频上进行定性评测。
- 主要结果:FaceCam在Ava-256数据集和野生视频上均优于TrajectoryCrafter、ReCamMaster等基线,在相机可控性、视觉质量和身份一致性上取得state-of-the-art表现。消融实验表明合成相机运动使模型学会平滑缩放/平移,多镜头拼接使模型学会跟随角度变化,野生视频数据则显著提升对真实光照和多样外观的泛化能力。代理头(proxy head)选择对性能影响极小,验证了关键点仅作为相机信号的设计正确性。
5. 创新、贡献与局限
💡 创新点:
- 提出面部尺度感知相机表示:以图像空间面部关键点位移作为相机条件,绕过3D重建误差和尺度歧义,实现确定性条件化
- 合成相机运动+多镜头拼接双策略:从静态训练相机数据中学习动态连续相机轨迹的生成能力
- 代理3D头部解耦设计:使用单一通用3D高斯头部作为推理时代理,关键点不携带身份信息,增强鲁棒性
🏆 主要贡献: - 面向人像视频的尺度感知相机表示方案,消除现有方法的几何畸变问题
- 两种互补的相机控制训练数据生成策略,利用静态多视角数据学习动态轨迹泛化
- 在Ava-256和野生视频上实现state-of-the-art的相机可控性与视觉保真度
⚠️ 局限性: - 仅当面部特征可见时才能检测关键点,无法处理相机旋转至头部背面的场景,也不适用于无人脸的通用场景
- 背景生成质量受限于训练数据(缺乏多视角一致的背景数据),背景合成不是本文重点
- 推理速度较慢,基于大型MoE视频扩散模型,不适合实时应用
6. 🚀 可迁移性启发
- 通用模型思路迁移:尺度感知图像空间对应关系作为相机表示的核心思路可迁移至其他人体或物体的新视角合成任务;利用图像空间关键点作为条件信号(而非世界坐标系位姿)的设计可推广到任何具有稳定可检测关键点的对象类别(如手、身体)。合成相机运动和多镜头拼接的数据扩充策略对其他需要相机控制但训练数据相机静态的任务同样适用。
- 研究方向迁移:1) 将尺度感知关键点条件化扩展到全身人像视频的相机控制;2) 结合深度估计改进背景生成;3) 模型蒸馏或轻量化视频生成主干以支持实时应用;4) 将图像空间对应关系思路扩展至一般场景(非人脸)的无3D先验相机控制
- 可视化思路借鉴:本文使用面部关键点可视化(关键点叠加在视频帧上)来直观展示相机条件信号;消融实验的对比图有效展示了不同训练策略对相机轨迹跟踪精度和视觉连续性的影响,这种分策略对比可视化方式对其他多组件方法的消融分析具有参考价值。
#02 STAvatar: Soft Binding and Temporal Density Control for Monocular 3D Head Avatars Reconstruction
⭐ 推荐 | 评分:
8.2/10| 领域:3D Head Avatar Reconstruction | arXiv · PDF
作者:Jiankuo Zhao, Xiangyu Zhu, Zidu Wang, Zhen Lei标签:
3D Gaussian Splatting·Head Avatar·UV Space·Adaptive Density Control·Monocular Reconstruction一句话总结:STAvatar提出UV自适应软绑定框架与时序密度控制策略,在单目视频的3D头部Avatar重建中显著提升细节保真度和遮挡区域重建质量。
1. 研究背景与动机
- 研究背景:基于3D高斯溅射(3DGS)的单目头部Avatar重建是计算机视觉与图形学的核心任务。现有方法通常将高斯基元绑定到FLAME网格的三角面片上,并仅通过线性混合蒙皮(LBS)建模变形,导致运动刚性、表达能力有限。此外,现有方法缺乏对嘴巴内部、眼睑等频繁遮挡区域的专项处理策略,在这些区域的重建质量较差。自适应密度控制(ADC)作为3DGS的关键机制,在与网格绑定的表示中难以有效应用。
- 研究问题:如何在保持与网格绑定的可动性基础上,设计支持动态自适应密度控制且对形状和纹理变化具有更强适应性的高斯表示,同时针对遮挡区域引入有效的密集化准则?
- 研究动机:高质量、可动画的3D头部Avatar在虚拟现实、视频会议、数字人等领域有广泛应用需求。现有方法在细节表达(如皮肤纹理、头发细节)和遮挡区域(如嘴部内侧、眼睑)的重建上仍有明显不足,直接影响渲染的真实感。提升这些方面不仅有学术价值,更有直接的产业应用价值。
2. 研究任务与图示
图注:Visualization of UV-Adaptive Sampling’s points.
3. 研究方法与核心架构
核心方法:STAvatar包含两个核心组件:
- UV自适应软绑定(UV-Adaptive Soft Binding)框架:不同于将高斯硬绑定到单个三角面片,本文在UV空间中为每个高斯基元预测特征偏移(feature offset)$\delta_i = {\delta_{\mu}, \delta_s, \delta_r, \delta_{\alpha}, \delta_c}$,分别控制位置、尺度、旋转、不透明度和颜色。各分量通过tanh/exp等有界激活函数约束在物理合理范围内。UV表示支持动态重采样,与ADC完全兼容,同时融合图像先验和几何先验学习偏移。对于无像素覆盖的三角面片,采用重心坐标分析性回退策略保证UV坐标赋值。
- 时序ADC(Temporal ADC, TADC)策略:(a) 帧时序聚类(FTC):使用轮廓系数自适应确定聚类数K,对视频帧进行t-SNE可视化验证的结构相似性聚类,每次ADC操作在各类别的平均密集化准则上计算,避免单帧噪声干扰。(b) 融合感知误差(Fused Perceptual Error, FPE):将传统几何误差(梯度)与结构相似性损失(d-SSIM,权重λ₁=0.2为最优)相融合,作为克隆准则,同时捕捉几何和纹理偏差,鼓励在需要精细细节的区域(包括遮挡区域)进行密集化。使用求和面积表(Summed-Area Table, SAT)将单高斯区域计算复杂度从O(R²)降至O(1),支持大规模实时优化。
图注:Overview of STAvatar. (a) In addition to a fixed identity reference image and its UV position map, we further rasterize the vertex offsets between reference mesh and control mesh to obtain a UV displa
4. 实验结果
- 实验设置:在4个基准数据集(含PointAvatar数据集及其他标准数据集)上评估。基线方法包括GaussianAvatars(GA)、RGBAvatar(RGBA)、Fate、FlashAvatar(FA)、SplattingAvatar(SA)、MonoGaussianAvatar(MGA)、PointAvatar等。评估指标:PSNR↑、SSIM↑、LPIPS↓。训练设置:STAvatar训练30个epoch(PointAvatar数据集为50 epoch),基线方法各自按官方配置收敛。
- 主要结果:STAvatar在4个数据集上均达到state-of-the-art,在最优超参数配置下(λ₁=0.2, M=1,聚类权重(0.3,0.6,0.1)):PSNR=30.63,SSIM=0.9587,LPIPS=0.0304。消融实验显示FPE的d-SSIM权重λ₁=0.2优于0.1和0.3;FTC随机训练轮数M=1优于M=0和M=2;聚类权重(0.3,0.6,0.1)为最优。t-SNE可视化证实FTC能有效将结构相似帧聚类,分离不同身份特征。
5. 创新、贡献与局限
💡 创新点:
- UV自适应软绑定:在UV空间预测有界特征偏移,使3DGS同时兼容ADC机制并具备更强的形状和纹理适应性
- 融合感知误差(FPE)作为克隆准则:联合几何(梯度)与纹理(d-SSIM)偏差指导密集化,改善遮挡区域细节
- 帧时序聚类(FTC):利用自适应聚类减少单帧噪声对密集化准则的干扰,提升时序稳定性
🏆 主要贡献: - UV自适应软绑定框架:支持动态ADC、融合图像和几何先验的per-Gaussian特征偏移学习方案
- 时序ADC策略:FTC帧聚类+FPE融合准则,针对性提升遮挡区域细节重建
- 在4个基准数据集上超越所有对比基线,实现单目3D头部Avatar重建的state-of-the-art性能
⚠️ 局限性: - 作为优化类(非前馈)方法,需要对每个身份单独优化,计算代价高,泛化能力有限
- UV表示依赖网格拓扑,对于无模板初始化场景不适用
- 对于极端表情或大角度遮挡(如完全侧脸),关键区域重建仍面临挑战
6. 🚀 可迁移性启发
- 通用模型思路迁移:UV空间特征偏移学习的软绑定思路可迁移至全身Avatar重建(如基于SMPL的高斯Avatar),在任意参数化网格上学习per-Gaussian的细粒度偏移。求和面积表(SAT)加速误差计算的工程技巧对其他需要密集估计高斯密集化准则的3DGS场景同样适用。FTC帧聚类减少优化噪声的思路对视频优化类任务(如动态NeRF、4D高斯)具有参考价值。
- 研究方向迁移:1) 将软绑定框架扩展至全身人体Avatar的3DGS重建;2) 将FPE准则与其他3DGS场景重建结合以改善细节区域;3) 探索基于学习的前馈预测初始化以减少per-identity优化时间;4) 将TADC策略应用于动态场景的4D高斯重建中
- 可视化思路借鉴:t-SNE聚类可视化直观验证了FTC策略的帧分组效果,这种利用降维聚类可视化来证明数据策略有效性的方式对其他涉及帧采样/筛选的视频重建方法有示范意义。offset map的空间可视化也为理解学习的几何偏差分布提供了有效手段。
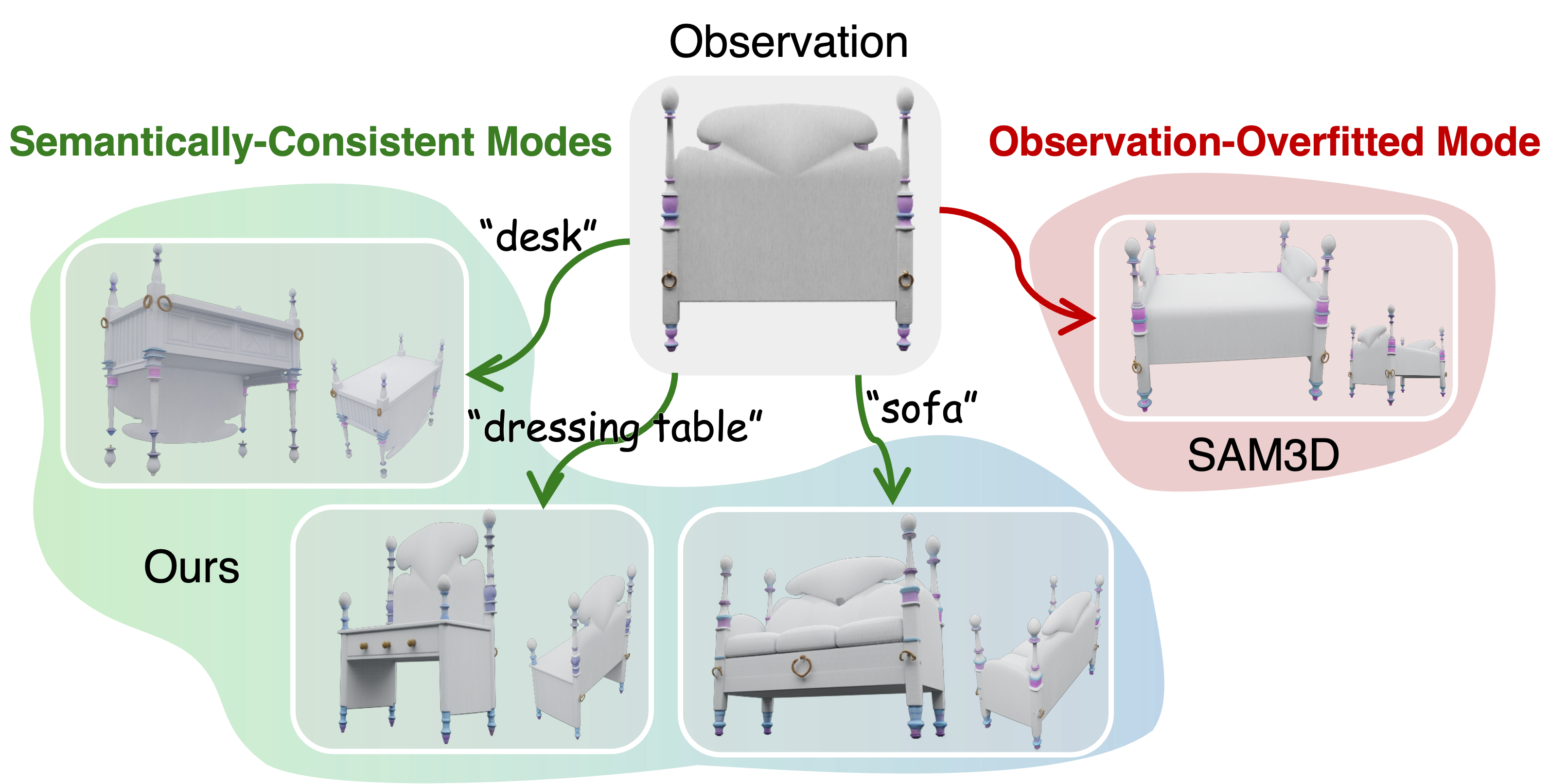
#03 MorphAny3D: Unleashing the Power of Structured Latent in 3D Morphing
⭐ 推荐 | 评分:
7.8/10| 领域:3D Generation / Morphing | arXiv · PDF
作者:Xiaokun Sun, Zeyu Cai, Hao Tang, Ying Tai, Jian Yang, Zhenyu Zhang标签:
3D Morphing·Structured Latent·Training-Free·Attention Manipulation·3D Generation一句话总结:MorphAny3D是首个基于结构化潜在表示(SLAT)的无训练3D形变框架,通过Morphing Cross-Attention和Temporal-Fused Self-Attention在3D生成器的注意力机制中融合源/目标特征,实现跨类别高质量3D变形序列。
1. 研究背景与动机
- 研究背景:3D形变(morphing)是动画、影视和游戏设计中的基础技术,要求源对象到目标对象的过渡在视觉上平滑、语义上合理。现有方法主要分两类:(1) 基于对应关系(matching-based)的方法,先建立源目标间稠密对应,再插值;但对应关系估计对跨类别场景(如椅子→汽车)容易失效,且忽略纹理演化。(2) 生成先验方法,将噪声或条件特征直接插值,缺乏对结构合理性和时序连续性的显式约束。近期Trellis等SLAT-based 3D生成框架取得了高质量3D生成,但SLAT表示在3D形变中的应用尚未被探索。
- 研究问题:如何充分利用SLAT表示中蕴含的3D生成先验,在无需任何训练的情况下,生成结构合理、时序平滑的高质量3D形变序列,并支持跨类别变形?
- 研究动机:3D内容创作对平滑形变的需求日益增长,但现有3D形变方法或受限于类内对应、或输出格式不兼容商业3D软件、或缺乏时序一致性。Trellis的SLAT表示拥有显式规则结构,天然支持无训练下游应用,为高质量跨类别3D形变提供了未被开发的强大潜力。
2. 研究任务与图示
图注:Comparison of different 3D morphing strategies. (a) Matching-Based 3D Morphing; (b) 2D Morphing + 3D Generation; (c) Direct Interpolation; (d) MorphAny3D. Our method leverages the powerful SLAT to ach
3. 研究方法与核心架构
核心方法:MorphAny3D构建于Trellis的image-to-3D变体之上,采用两阶段(SS阶段→SLAT阶段)生成流程。核心方法包含三个模块:
- **Morphing Cross-Attention (MCA)**:在Trellis SLAT流变换器的cross-attention层,将源对象和目标对象的SLAT特征以变形权重α∈[0,1]加权融合,替代原始单一对象的cross-attention,确保中间形变在结构上同时来自源和目标,保证视觉连贯性和美学合理性。
- **Temporal-Fused Self-Attention (TFSA)**:在self-attention层,将前一帧的SLAT特征注入当前帧的自注意力计算,使当前帧在生成时参考已生成的前序帧,从而在时序维度上强制连续性,消除帧间跳变。
- 方向校正策略(Orientation Correction):基于对Trellis生成的3D资产方向分布的统计分析,识别并修正形变过程中因方向歧义导致的突变方向变化,进一步提升形变平滑度。整个框架无需额外训练,直接在Trellis推理时修改注意力计算即可实现3D形变,并可无缝迁移到其他SLAT-based模型。
图注:(a) Overview of our method. MorphAny3D generates a smooth and high-quality morphing sequence between diverse object categories by leveraging the SLAT representation without any training. (b) Morphing
4. 实验结果
- 实验设置:定性与定量评估覆盖同类别和跨类别(如蜜蜂→双翼飞机)形变场景。与基线方法对比:(a) 基于对应关系的传统3D形变;(b) 2D morphing + 3D生成(逐帧独立提升到3D);(c) 直接插值Trellis初始噪声和条件特征(类似3DMorpher)。评估维度包括结构合理性、时序平滑度、跨类别泛化能力和视觉美观性。同时展示扩展应用:解耦形变(decoupled morphing)和3D风格迁移(3D style transfer)。
- 主要结果:MorphAny3D在同类别和跨类别形变上均优于所有基线方法。(a) 基于对应关系的方法在跨类别场景下因对应估计失败产生结构扭曲;(b) 逐帧2D→3D方式缺乏时序一致性;(c) 直接插值方式缺乏结构约束。MorphAny3D生成的形变序列在结构合理性、时序连续性和视觉美观性上均最优,能处理蜜蜂→双翼飞机等极端跨类别场景,并支持解耦形变和风格迁移等高级应用。
5. 创新、贡献与局限
💡 创新点:
- 首个基于SLAT表示的无训练3D形变框架:直接在3D生成器注意力机制中融合源/目标特征,无需匹配对应关系
- MCA+TFSA双注意力机制:分别从跨对象结构融合(MCA)和时序连续性(TFSA)两个维度提升形变质量
- 基于SLAT方向统计分布的方向校正策略:消除形变过程中的方向突变问题
🏆 主要贡献: - MorphAny3D:首个无训练SLAT-based 3D形变框架,支持任意类别间的高质量形变
- MCA和TFSA:两个轻量级注意力修改模块,利用SLAT跨对象和跨帧特征改善形变质量
- 方向校正策略及对SLAT注意力融合规律的深入分析,为SLAT-based下游任务提供方法论参考
⚠️ 局限性: - 依赖Trellis模型,形变质量受底层生成器能力限制,对于Trellis无法良好生成的对象类别效果可能下降
- 无训练框架在特定场景下的结构合理性不如专门训练的模型精确
- 方向校正策略基于统计启发式,可能在分布外的特殊对象上失效
6. 🚀 可迁移性启发
- 通用模型思路迁移:在生成模型注意力机制中融合多源特征以控制生成结果的思路,可迁移至视频生成(帧插值)、图像编辑(内容混合)以及其他SLAT-based模型的下游任务(如3D编辑、风格化)。TFSA利用前帧特征引导当前帧生成的时序一致性机制,对其他序列化生成任务(如视频生成的帧间一致性)具有参考价值。
- 研究方向迁移:1) 将MCA/TFSA思路扩展至视频级别的帧插值和补帧任务;2) 探索SLAT表示在4D动态物体生成和变形中的应用;3) 将注意力融合机制与用户控制(如文本引导)结合实现可控3D形变;4) 迁移框架至其他SLAT-based模型(如HiScene)
- 可视化思路借鉴:论文的分策略对比图(图2/comp图)系统展示了四种策略的形变质量差异,这种多方法横向对比可视化模式对展示方法论演进非常有效。Teaser图展示跨类别形变序列(包括极端案例如蜜蜂→双翼飞机),有助于直观传达方法能力,值得借鉴用于其他生成类论文。
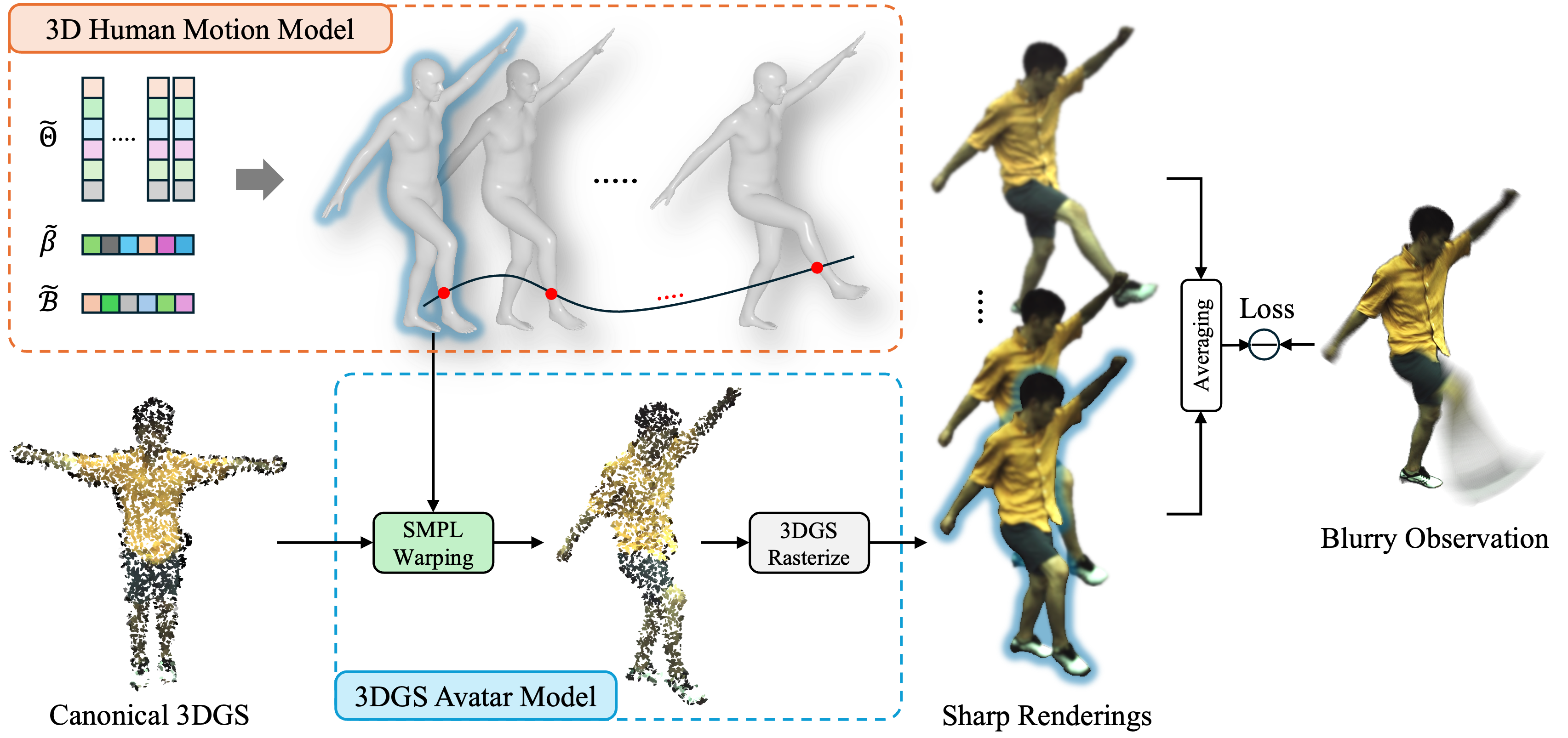
#04 Motion-Aware Animatable Gaussian Avatars Deblurring
⭐ 推荐 | 评分:
7.5/10| 领域:3D Human Avatar Reconstruction | arXiv · PDF
作者:Muyao Niu, Yifan Zhan, Qingtian Zhu, Zhuoxiao Li, Wei Wang, Zhihang Zhong, Xiao Sun, Yinqiang Zheng标签:
3D Gaussian Splatting·Motion Blur·Human Avatar·SMPL·Deblurring一句话总结:MAD-Avatar首次提出从模糊视频直接重建清晰可动画3D人体高斯Avatar的方法,通过3D感知模糊生成模型与B-spline插值运动模型的联合优化,解决运动模糊引入的歧义问题。
1. 研究背景与动机
- 研究背景:基于3DGS和SMPL的3D人体Avatar重建方法已取得显著进展,但现有技术均依赖高质量清晰图像作为输入。在真实场景中,由于人体运动速度和强度的不可预测性,运动模糊不可避免。虽然可先用2D去模糊技术处理后再重建,但2D去模糊忽略了3D场景内在信息,在多视角间产生不一致性,进一步降低Avatar重建质量。此前针对3D场景(NeRF/3DGS)的去模糊方法仅处理静态场景,无法重建可动画的人体Avatar。
- 研究问题:如何从多视角模糊视频中直接重建高质量、清晰、可动画的3D人体高斯Avatar?核心挑战在于:运动模糊在像素空间引入严重的运动歧义(同一模糊图像可由多种运动轨迹产生),且现有Avatar模型的SMPL参数估计在模糊帧上会产生错误。
- 研究动机:现实录制中运动模糊普遍存在,若无法处理模糊输入,3D Avatar技术的实用性将大打折扣。直接从模糊视频重建Avatar(无需预处理去模糊)既能保留3D一致性,又能联合优化运动估计,从根本上解决歧义问题,具有重要的实用价值。
2. 研究任务与图示
图注:The ambiguity brought by motion blur. When reconstructing sharp 3DGS avatars from blurry frames, motion-induced blur introduces challenging ambiguities in motion interpretation. fig:d
3. 研究方法与核心架构
核心方法:MAD-Avatar的核心包含两个相互耦合的建模组件:
- 3D感知模糊生成模型(3D Blur Formation Model):将物理模糊过程从2D图像坐标空间扩展到3D人体Avatar建模框架。模糊图像被建模为曝光时段内T个虚拟清晰图像的平均:I^B = (1/T)∑_{t=0}^{T-1} R(W({G_k(x)}, S_t), R, K),其中W为从正则空间到观测空间的SMPL驱动变形算子,R为3DGS光栅化渲染器。这使得模糊生成过程在3D Avatar层面完全可微分,支持端到端联合优化。
- 3D人体运动模型(3D Human Motion Model):(a) 子帧刚性序列位姿模型(Sub-frame Rigid Sequential Pose Model):对SMPL的24个关节分别定义P个控制节点,使用B-spline(De Boor-Cox公式)插值曝光时段内的中间位姿,实现平滑运动轨迹建模;(b) 位姿变形模型(Pose Deformation Model):在B-spline插值基础上引入per-joint per-timestep的位姿位移Δ^j_t,通过轻量级网络G_disp预测,捕捉高频非刚性位姿变化;(c) 帧间全局运动(Inter-frame Global Motion):估计帧间全局刚体运动以处理相机和人体的整体位移。联合优化从粗略SMPL初始化出发,迭代优化3DGS Avatar表示和运动参数,最终渲染虚拟清晰图像序列的平均来匹配观测模糊帧。
4. 实验结果
- 实验设置:实验分两个数据集:(1) 合成数据集:基于ZJU-MoCap数据集构建,通过对清晰视频施加真实物理模糊合成模糊帧,提供有Ground Truth的定量评估;(2) 真实数据集:使用自建的360度同步混合曝光相机系统采集,包含4个模糊相机(曝光50ms)和8个清晰相机(曝光3.125ms),分辨率2448×2048,8个场景。基线包括:2D去模糊预处理+标准Avatar重建方法(两阶段基线)。额外提供iPhone 16 Pro的DIY演示。评估指标包括视觉质量(PSNR/SSIM/LPIPS)和运动估计准确性。
- 主要结果:MAD-Avatar在合成数据集和真实数据集上均显著优于两阶段基线(先2D去模糊再重建)和直接使用模糊帧重建的方法。混合曝光相机系统提供的清晰参考图像验证了重建清晰度的可信度。方法能有效处理不同运动强度和速度下的模糊情况,在多种条件下展示了鲁棒性。
5. 创新、贡献与局限
💡 创新点:
- 将物理模糊生成过程从2D扩展到3D Avatar建模空间,构建完全可微的3D感知模糊模型
- B-spline子帧位姿插值+位姿位移网络的两级运动模型,有效解决运动歧义问题
- 构建首个用于模糊Avatar重建的基准数据集:合成数据集+真实360度混合曝光采集系统
🏆 主要贡献: - 首个从模糊多视角视频直接重建清晰可动画3D人体高斯Avatar的完整框架
- 3D感知模糊生成模型:将模糊过程联合编入Avatar优化目标,保持3D多视角一致性
- 新型基准数据集:合成ZJU-MoCap模糊数据集+自建真实360度混合曝光数据集
⚠️ 局限性: - 仍依赖多视角输入(multi-view),不支持单目视频的模糊Avatar重建
- B-spline运动模型假设运动连续平滑,对极端非线性运动(如剧烈跳跃)的建模能力有限
- 优化过程计算代价较高,且需要EasyMocap等工具提供的粗略SMPL初始化
6. 🚀 可迁移性启发
- 通用模型思路迁移:将物理模糊过程集成到3D表示的优化目标中(而非预处理去模糊)的思路,可推广至其他动态3D场景(如户外运动场景、动物运动)的去模糊重建。B-spline子帧插值运动建模方法可迁移至其他需要亚帧运动估计的任务(如高速摄影分析、帧率提升)。混合曝光相机系统设计为真实场景去模糊评估提供了可复用的硬件基准方案。
- 研究方向迁移:1) 扩展至单目视频的模糊Avatar重建;2) 将3D模糊模型应用于动态场景(非Avatar)的4D高斯重建;3) 结合事件相机数据改进极端运动下的运动估计;4) 将混合曝光设计推广至更多3D重建基准数据集构建
- 可视化思路借鉴:论文的模糊歧义示意图(图1)直观展示了同一模糊图像可由多种运动轨迹解释的歧义问题,这种物理直觉驱动的可视化对引入问题背景非常有效。流水线图将B-spline运动→变形Avatar→模糊合成→损失计算串联展示,清晰呈现了端到端框架的数据流,值得其他联合优化类方法借鉴。
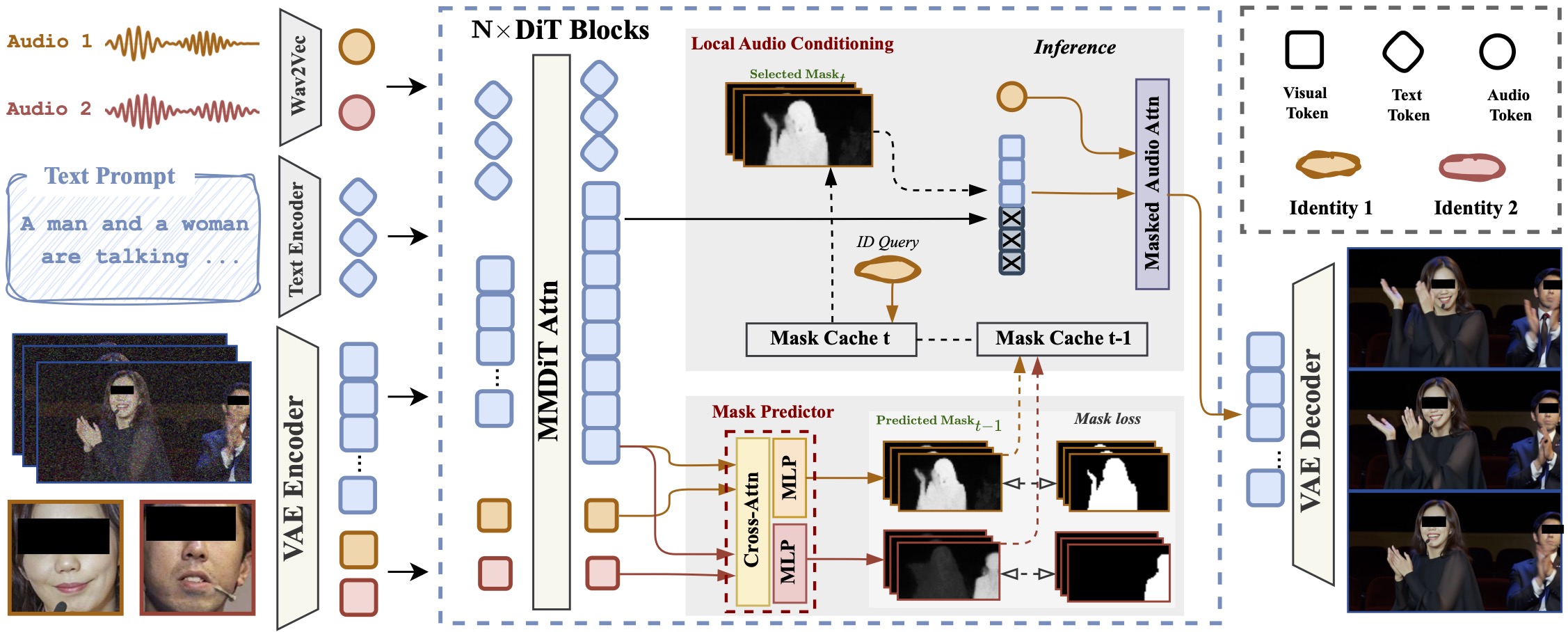
#05 InterActHuman: Multi-Concept Human Animation with Layout-Aligned Audio Conditions
⭐ 推荐 | 评分:
8.0/10| 领域:Human Video Generation | arXiv · PDF
作者:Zhenzhi Wang, Jiaqi Yang, Jianwen Jiang, Chao Liang, Gaojie Lin标签:
Multi-Concept Generation·Human Animation·Audio-Driven·Layout Alignment·Video Diffusion一句话总结:InterActHuman提出迭代掩码预测机制,将多模态条件(参考图像+文本+音频)与各身份的空间布局精确对齐,首次实现多人/人-物交互场景下的高质量端到端人体动画生成。
1. 研究背景与动机
- 研究背景:基于扩散变换器(DiT)的端到端人体动画方法在音频驱动的单人人像生成上已取得高质量成果,但几乎所有现有方法都局限于单身份假设:所有条件信号(参考图像、音频)被全局注入,默认描述同一个人。现实场景中往往涉及多人对话、人-物交互等多概念场景,全局注入策略导致条件与空间位置的错配——尤其是音频信号,它与特定说话人强相关,不应全局共享。现有多概念视频定制方法(Video-Alchemist、ConceptMaster、Phantom等)同样采用视频级条件注入,缺乏局部条件的精确绑定能力。
- 研究问题:如何在多概念(多人/人-物)场景下,将各身份的视觉参考(图像)、全局文本描述以及局部音频条件分别精确绑定到对应身份在视频时空中的空间区域(spatiotemporal footprint)?推理时因最终视频未知而导致的「先有鸡还是先有蛋」困境(布局未知→无法注入音频→无法生成视频→布局未知)如何打破?
- 研究动机:多人对话视频生成、多概念人-物交互场景是人体动画的重要应用方向,但现有单身份假设框架无法应对。将局部音频条件与正确说话人空间区域对齐是生成真实感多人对话视频的关键,同时也是构建能支持多模态(图像+文本+音频)多概念生成框架的重要基础。超200万视频-实体对的大规模数据集构建也填补了该方向的数据空白。
2. 研究任务与图示
图注:Video frames generated from audio and multi-concept reference images (human heads/full bodies, objects, scenes) display rich, audio-matched expressions. Our method enables compositional generation inc
3. 研究方法与核心架构
核心方法:InterActHuman构建于MMDiT-based视频扩散模型之上,采用Flow Matching目标训练。核心设计包含两个模块:
- 掩码预测器(Mask Predictor):在扩散Transformer中引入一个cross-attention掩码预测分支,以去噪视频潜码和参考图像潜码的特征为输入,预测每个概念在输出视频中对应的空间掩码(mask)。该预测器由Ground-Truth掩码监督训练。通过显式预测布局,使模型能将各参考图像与其在视频中的精确位置对齐。
- 迭代掩码预测策略(Interleaved Mask Prediction):打破「先有鸡还是先有蛋」困境:在扩散去噪过程中,步骤k预测的掩码指导步骤k+1的条件注入。具体地:(a) 全局条件(参考图像)在整个去噪过程中注入全局注意力;(b) 局部音频条件通过带掩码的音频注意力(Masked Audio Attention)注入到对应身份的空间区域,掩码由上一步的掩码预测器动态更新。随着去噪步骤推进,布局逐步精细化,最终收敛到准确的空间对齐,无需GT视频。
- 数据构建流程:构建超200万视频-实体对数据集,通过身份追踪提取掩码和图像,通过唇形同步对齐各身份的音频片段,覆盖人-人和人-物交互场景。
4. 实验结果
- 实验设置:评估场景包括:(1) 2-3人对话视频生成;(2) 多参考图像的视频定制(含服装替换、人-物交互、动漫风格);(3) 无起始帧的对话生成。与基线对比:ConceptMaster、Video-Alchemist、Phantom、SkyReels-A2等多概念定制方法,以及EchoMimic、Hallo等单人音频驱动方法。评估指标包括视觉质量、音频-唇形同步精度、身份一致性、布局对齐准确性等。消融实验验证显式布局控制相对于隐式对照的优势。
- 主要结果:InterActHuman在多概念多人对话视频生成上显著优于现有基线。消融实验证明显式掩码预测+迭代注入策略(explicit layout control)在布局对齐精度和音频同步质量上明显优于隐式条件注入(implicit counterpart)。方法能生成带有正确唇形同步(红/绿波形图标分别标注说话/聆听)的多人对话视频,并支持服装定制、人-物交互和动漫风格等多样化应用。
5. 创新、贡献与局限
💡 创新点:
- 首个支持多人/人-物交互的多概念端到端人体动画框架,突破单身份假设,实现局部音频条件的精确空间绑定
- 迭代掩码预测策略:打破「先有鸡还是先有蛋」困境,在去噪过程中逐步精细化布局,无需GT视频即可实现精确空间对齐
- 构建超200万视频-实体对的大规模多概念人体动画数据集,含人-人和人-物交互场景及对齐音频
🏆 主要贡献: - InterActHuman框架:首个支持多概念(多人/人-物)、多模态(图像+文本+音频)的端到端人体动画生成方法
- 显式空间布局控制:掩码预测器+迭代注入策略,将局部音频精确绑定到对应身份的时空区域
- 大规模多概念人体动画数据集:200万+视频-实体对,填补多概念人体动画训练数据空白
⚠️ 局限性: - 迭代掩码预测增加推理计算量,每步去噪需额外运行掩码预测分支
- 掩码预测的准确性依赖去噪中间特征的质量,在严重遮挡或高度相似外观的多人场景下可能产生误匹配
- 当前设计主要针对2-3个概念,在概念数量更多时性能可能下降
6. 🚀 可迁移性启发
- 通用模型思路迁移:迭代掩码预测的「条件-空间对齐」机制可迁移至任何需要局部条件精确绑定的视频生成场景(如多物体的独立轨迹控制、场景级语义分割引导的生成)。在扩散去噪步骤中逐步精细化布局的迭代策略,可推广至其他需要在推理时动态确定条件区域的生成框架。大规模自动化数据构建流水线(身份追踪+唇形同步)对构建其他视频生成数据集具有参考价值。
- 研究方向迁移:1) 将局部条件注入框架扩展至更多模态(深度、姿态、3D信息)的精确区域绑定;2) 探索多概念视频生成中的概念间交互建模(如碰撞、接触);3) 将迭代布局精细化策略应用于训练时间步粗到细的渐进式生成;4) 基于构建的数据流水线扩展至更大规模和更多样化的多人视频数据集
- 可视化思路借鉴:论文的Teaser图用红/绿波形图标标注说话/聆听状态,直观展示了音频-身份对齐效果,这种利用视觉标注直接在示例图上呈现任务核心属性的方式对其他涉及多模态对齐的工作有参考价值。音频全局注入vs局部注入的对比图(图2/audio图)清晰地展示了条件错配问题,是引出方法动机的有效可视化手段。
📋 其余论文简报(#06 – #20)
#06 EasyAnimate: High-Performance Video Generation Framework with Hybrid Windows Attention and Reward Backpropagation
⭐ 推荐 | 评分:
8.0/10| 领域:Video Generation | arXiv · PDF
作者:Jiaqi Xu, Xinyi Zou, Jiaxin Wang, Wenbing Zhu, Haoran Feng, Bocheng Ren标签:
Video Generation·Diffusion Transformers·Sliding Window Attention·Reward Backpropagation·Human Preference Alignment一句话总结:EasyAnimate是一个高效高质量视频生成框架,通过混合窗口注意力机制、奖励反向传播后训练以及多模态大语言模型文本编码器,在VBench排行榜和人类评估上均达到最先进性能。
图注:The EasyAnimate pipeline comprises four stages: data preprocessing, VAE Training, DiT Training and Post Training.
研究背景与方法
- 研究背景:视频扩散模型领域已取得重大进展,但现有视频生成模型仍面临两大主要挑战:一是训练效率低、推理速度慢,原因在于Transformer架构的计算复杂度随序列长度二次增长;二是视频质量不理想,体现在美学风格与人类偏好不一致以及文本提示遵循精度不足。早期基于U-Net的方法逐渐被Diffusion Transformer架构取代,但后者的高计算成本制约了实际应用。解耦时空注意力虽可降低复杂度,但损害了感受野和视频质量;全3D注意力虽质量较高,却需要大量计算资源。
- 研究问题:如何在不牺牲视频生成质量的前提下,显著提升视频扩散Transformer的训练效率和推理速度,同时改善生成视频与人类偏好的对齐程度?
- 核心方法:EasyAnimate框架包含四个核心阶段:数据预处理、VAE训练、DiT训练和后训练。核心技术贡献包括:(1) 混合窗口注意力(Hybrid Window Attention):提出多方向滑动窗口注意力模块,在时间和空间三个维度上扩大感受野,并与全注意力层交替排列以平衡效率和质量,相比朴素的全注意力方案降低了随视频序列长度增加的计算复杂度;(2) 基于Token长度的训练策略(Training with Token Length):确保每个训练样本具有相同的最大token数,解决了不同分辨率和帧数视频训练时GPU利用率不均的问题;(3) 奖励反向传播后训练(Reward Backpropagation Post-Training):探索组合多种可微奖励模型对生成的视频进行优化,将其适配到基于3D因果VAE和整流流采样的Transformer架构,并设计了关键修改以保证训练稳定性和视频动感;(4) 采用Qwen2-VL作为多模态大语言模型文本编码器,显著提升了模型对详细文本描述和复杂对象关系的理解能力。
图注:The EasyAnimate pipeline comprises four stages: data preprocessing, VAE Training, DiT Training and Post Training.
- 🚀 研究方向迁移:可探索将此框架扩展到音频-视频联合生成、3D视频生成等领域;可研究更自动化的奖励模型选择和组合策略;可将多方向滑动窗口注意力应用于其他视频理解任务如动作识别和视频问答。
#07 Text-to-3D by Stitching a Multi-view Reconstruction Network to a Video Generator
⭐ 推荐 | 评分:
7.8/10| 领域:Text-to-3D Generation | arXiv · PDF
作者:Hyojun Go, Dominik Narnhofer, Goutam Bhat, Prune Truong, Federico Tombari, Konrad Schindler标签:
Text-to-3D·Model Stitching·Gaussian Splatting·Video Diffusion·Reward Finetuning一句话总结:VIST3A提出了一种通过’模型缝合’将大型文本到视频生成器与前馈3D重建网络对接的通用框架,无需大量标注数据即可实现高质量文本到3D生成并显著超越现有方法。
图注:. Video models excel at generating latent visual content from text prompts, whereas 3D foundation models shine when it comes to decoding such a la
研究背景与方法
- 研究背景:大型预训练视觉内容生成模型(文本到视频)和3D重建系统(如NeRF、3DGS)的快速进步为文本到3D生成开辟了新可能。现有文本到3D方法通常采用流水线式设计:先生成多视角图像,再进行3D重建,但两个阶段独立训练导致误差积累(视角不一致、纹理闪烁)和对潜空间扰动的鲁棒性不足。另一类方法采用逐场景优化,推理开销巨大。如何将视频生成器强大的语义知识与3D重建网络的几何能力有机结合,是当前3D生成领域的核心挑战。
- 研究问题:如何保留预训练文本到视频模型和前馈3D重建模型各自的丰富知识,同时将两者有效对接,使视频潜变量能够被3D解码器直接解码为高质量、一致的3D场景?
- 核心方法:VIST3A框架解决两个核心挑战:(1) 模型缝合(Model Stitching):在3D解码器中搜索与文本到视频生成器产生的潜变量表示最匹配的层,通过单个Conv3D缝合层将视频VAE的潜特征对齐到3D模型的特征空间。该操作仅需少量无标注数据(如200-3200个场景)完成,缝合层初始化时对输入进行插值后再应用3D卷积,以保证空间和时间维度的对齐。训练损失为缝合VAE输出与原始3D模型输出之间的加权L1损失,对不同3D模型输出分量(点图、高斯原语、置信度等)采用不同权重以平衡训练稳定性。(2) 直接奖励微调(Direct Reward Finetuning):对文本到视频生成器进行微调,使生成的潜变量可被缝合的3D解码器正确解码为感知上令人信服的3D场景。奖励由三部分组成:多视角图像质量奖励(CLIP+HPSv2.1)、3D表示质量奖励和3D一致性奖励(L1+LPIPS)。采用DRTune风格的选择性梯度计算保证训练稳定性,仅在K=2个采样步骤计算梯度。该框架通用,已在VGGT、AnySplat、MVDUSt3R三种3D重建模型上验证。
图注:Stitching repurposes a part of a pretrained 3D vis
- 🚀 研究方向迁移:可探索更复杂的缝合层架构(而非单Conv3D)以提升对齐精度;可研究将此范式扩展到4D(动态3D)生成;可将奖励模型扩展到包含物理合理性的评估,如光照一致性、物理碰撞等。
#08 RelaxFlow: Text-Driven Amodal 3D Generation
⭐ 推荐 | 评分:
7.5/10| 领域:3D Generation | arXiv · PDF
作者:Anonymous Authors标签:
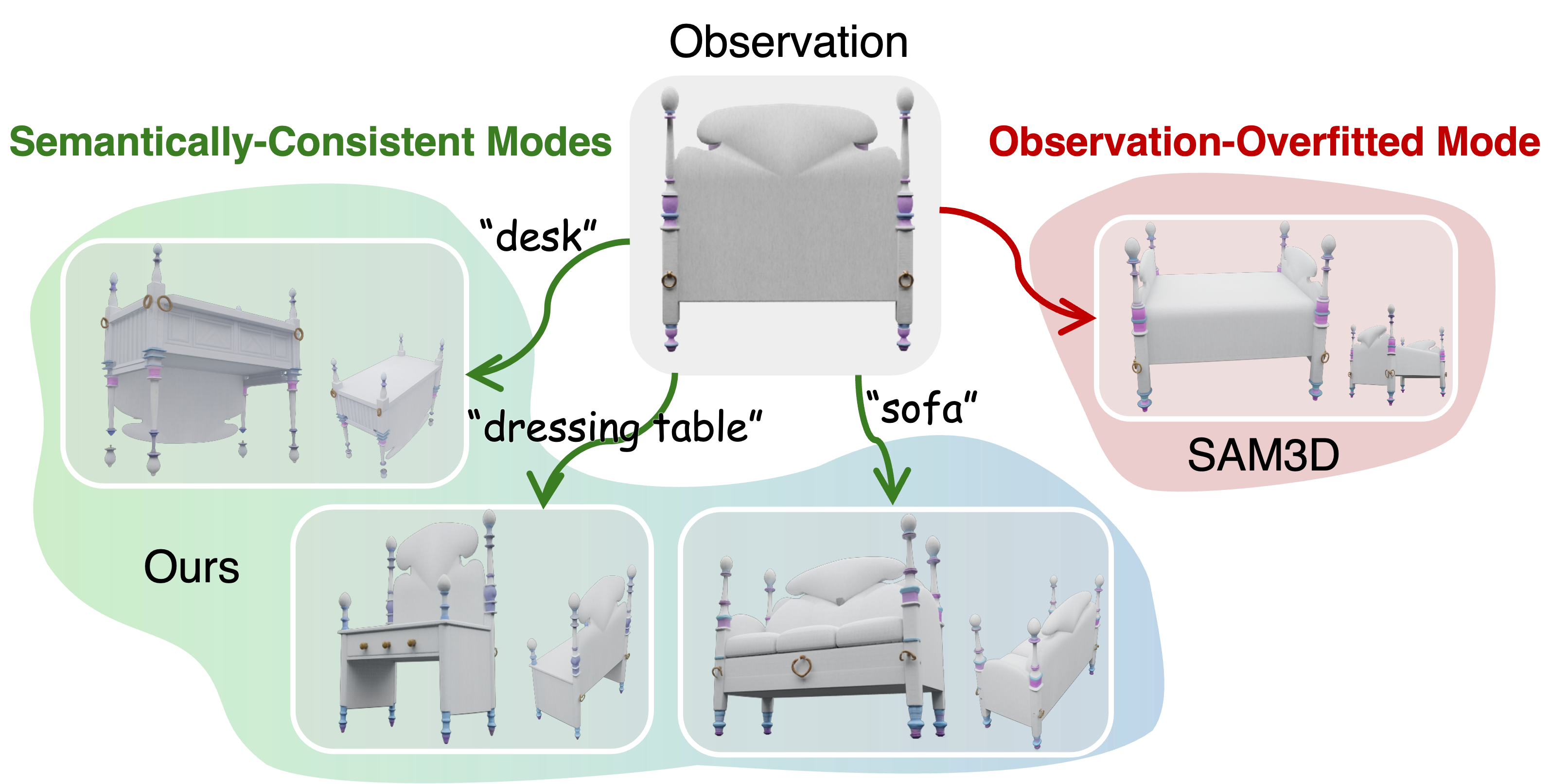
Amodal 3D Generation·Text-driven Generation·Flow Matching·Training-free·Occlusion Completion一句话总结:RelaxFlow是一个无需训练的双分支框架,通过多先验共识模块和松弛机制解耦观测区域的刚性控制与文本引导的松弛结构控制,实现在严格保真已知区域的同时用文本提示驱动遮挡区域的3D补全。
研究背景与方法
- 研究背景:图像到3D生成在遮挡场景下面临固有的语义歧义性:仅凭部分观测往往不足以确定物体类别。当输入图像中物体被严重遮挡时,缺失区域的3D结构和外观存在多种合理解释,需要额外的语义信息来引导补全方向。现有方法通常仅依赖单一输入图像,缺乏对遮挡区域的语义控制能力,容易产生语义不一致或视觉失真的3D结果。如何在保持已知区域严格保真的同时,允许文本提示灵活引导未知区域的生成,是本文要解决的核心问题。
- 研究问题:在单图像到3D生成任务中,如何实现’严格保真已观测区域’和’文本语义引导遮挡区域补全’这两个看似矛盾的目标,即如何对观测区域和文本提示施加不同粒度的控制?
- 核心方法:RelaxFlow提出无需训练的双分支框架,核心设计包含两个模块:(1) 多先验共识模块(Multi-Prior Consensus Module):融合来自观测图像和文本提示的多个先验信号,对观测区域施加刚性(精确)控制,确保生成结果严格保留输入的视觉细节;(2) 松弛机制(Relaxation Mechanism):对文本提示引导的生成向量场施加低通滤波,理论上等价于对生成向量场进行高斯模糊,从而抑制高频的实例细节(如具体纹理和形状),仅保留低频的几何结构信息,使生成的遮挡区域在几何结构上与观测区域兼容同时遵循文本语义。理论分析证明:松弛操作等价于对生成向量场施加低通滤波器,该分析基于最优传输理论(Wasserstein-2距离)和Lipschitz条件下的ODE流稳定性引理,通过谱分析建立了语义信号(低频)与实例细节误差(高频)的分离性质。为便于评估,论文还引入两个新诊断基准:ExtremeOcc-3D(极端遮挡场景)和AmbiSem-3D(语义歧义场景)。
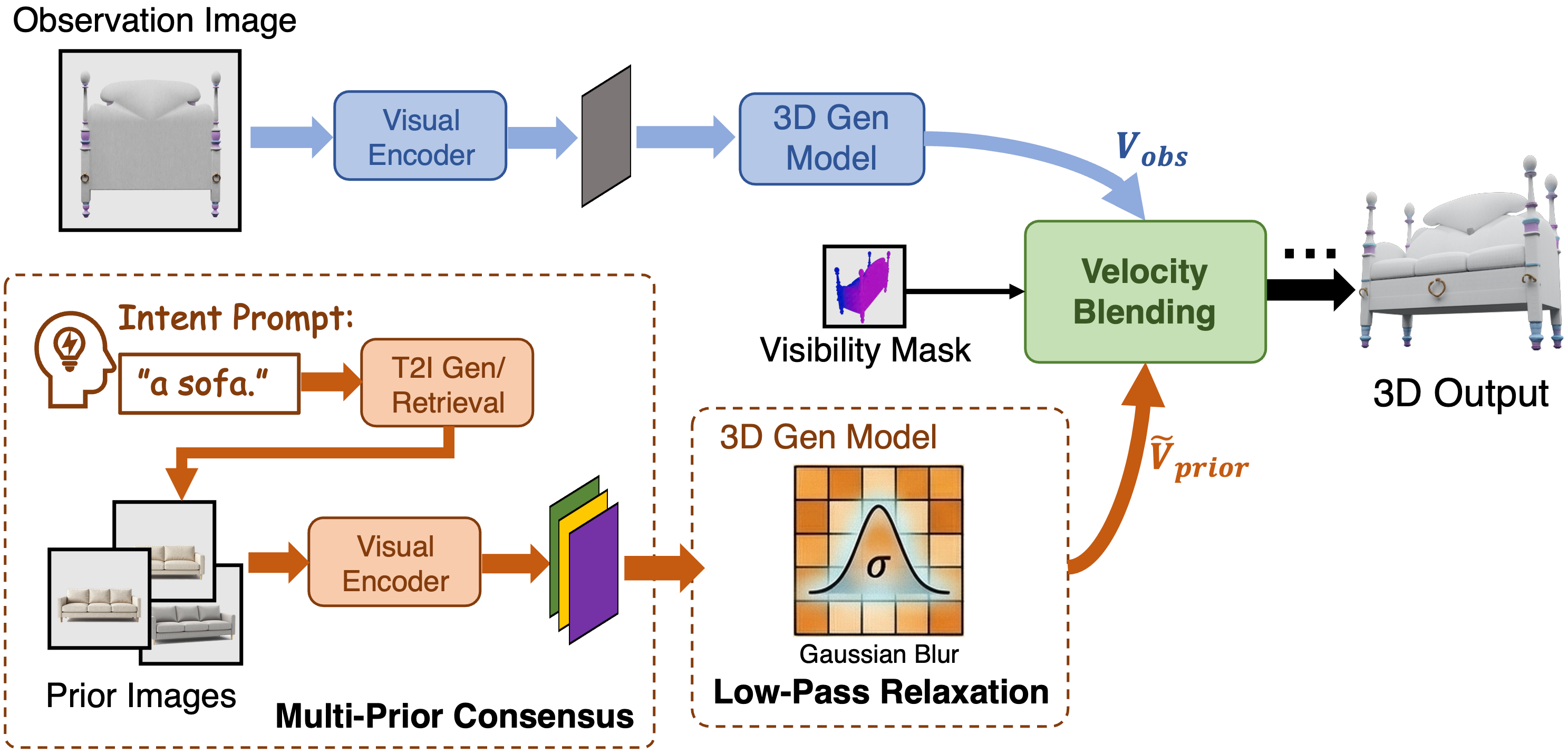
- 🚀 研究方向迁移:可探索将松弛机制扩展到视频补全(temporal amodal completion)任务;可研究自适应低通滤波参数根据遮挡程度动态调整;可将双分支控制框架应用于3D场景编辑,支持局部语义修改同时保持整体一致性。
#09 DiffusionHarmonizer: Bridging Neural Reconstruction and Photorealistic Simulation with Online Diffusion Enhancer
⭐ 推荐 | 评分:
7.8/10| 领域:Neural Simulation / Autonomous Driving | arXiv · PDF
作者:Yuxuan Zhang, Katarina Tothova, Zian Wang, Kangxue Yin, Haithem Turki, Yu Chang, Ricardo Martin-Brualla, Sanja Fidler, Nicolas Chapados标签:
Neural Simulation·Diffusion Enhancement·Temporal Consistency·Image Harmonization·Autonomous Driving一句话总结:DiffusionHarmonizer是一个在线生成增强框架,将预训练扩散模型蒸馏为单步时序条件增强器,将神经重建(NeRF/3DGS)的渲染结果实时转换为时序一致的真实感图像,推理速度达212ms,大幅超越现有编辑基线。
图注:of the data curation pipeline () and model architecture () of . We use a single-step temporally conditioned enhancement model, that is converted
研究背景与方法
- 研究背景:神经重建技术(NeRF、3D Gaussian Splatting)正在成为自动驾驶等机器人系统仿真的重要方案,能够从真实世界数据自动化、可扩展地生成仿真场景。然而,这些方法在渲染新视角时常出现伪影,尤其是在插入来自不同场景的动态物体时,光照和阴影等物理属性的不一致问题严重影响了仿真的真实性。现有图像/视频编辑模型(如SDEdit、InstructPix2Pix)虽可改善外观,但存在内容幻觉、时序不一致以及过度编辑已良好重建区域等问题。
- 研究问题:如何在在线仿真环境中(单GPU实时运行),将神经重建生成的不完美渲染结果转换为时序一致、真实感强的输出,同时保持场景几何结构和输入内容的高保真度?
- 核心方法:DiffusionHarmonizer的核心是将预训练多步图像扩散模型(Cosmos 0.6B text-to-image,0.6B参数扩散骨干+0.14B参数VAE分词器)转换为单步时序条件增强器。训练流程:(1) 非时序预训练(10k步):在合成-真实图像对上训练,损失函数结合L2重建损失(λ=1)和感知损失LPIPS(λ=1),目标是学习外观和谐化、伪影修正和光照真实感;(2) 时序微调(4k步):额外引入时序条件,确保相邻帧间的一致性,在1024×576分辨率下以bf16精度训练,冻结VAE分词器仅微调扩散骨干。数据构建是关键:自定义数据管理流水线生成合成-真实图像对,重点覆盖外观和谐化、伪影修正和光照真实感三类场景。在评估中对比了SDEdit(SD3)、InstructPix2Pix、Wan-Video V2V(基于WAN 2.1)三类通用编辑基线,以及Ke等人、VHTT两类专用视频和谐化方法。
图注:of the data curation pipeline () and model architecture () of . We use a single-step temporally conditioned enhancement model, that is converted
- 🚀 研究方向迁移:可探索将DiffusionHarmonizer扩展到更高分辨率(如4K)或更长时间跨度的时序一致性;可研究将增强器与神经重建网络端到端联合训练以进一步提升保真度;可将此框架应用于虚拟现实环境渲染增强。
#10 MotionStream: Real-Time Video Generation with Interactive Motion Controls
⭐ 推荐 | 评分:
8.2/10| 领域:Video Generation | arXiv · PDF
作者:Joonghyuk Shin, Zhengqi Li, Richard Zhang, Jun-Yan Zhu, Jaesik Park, Eli Shechtman, Xun Huang标签:
Streaming Video Generation·Motion Control·Knowledge Distillation·Causal Attention·Real-time Generation一句话总结:MotionStream实现了亚秒级延迟、最高29FPS的实时交互式运动控制视频生成,通过将双向教师模型蒸馏为因果学生模型,并结合滑动窗口因果注意力与注意力汇聚,支持无限长视频流式生成。
图注:Prior motion-controlled video diffusion models typically operate offline to generate fixed-length sequences in parallel (top left). In contrast, our enables streaming long-video generation
研究背景与方法
- 研究背景:当前运动条件视频生成方法存在两大核心局限:一是推理延迟极高(通常需要数分钟生成一段视频),无法支持实时交互;二是采用非因果处理方式,模型需要看到完整的输入序列才能生成输出,根本上阻碍了流式推理的可能性。用户期望能像使用交互式工具一样实时预览运动轨迹的效果,但现有方法无法满足这一需求。此外,长视频生成面临上下文窗口无限增长导致计算成本持续上涨的问题,以及长序列推理时的误差积累问题。
- 研究问题:如何在单GPU上实现亚秒级延迟的实时运动控制视频流式生成,同时支持无限长度视频的稳定生成,并保持与非实时方法相当的视频质量?
- 核心方法:MotionStream的方法分为两个阶段:(1) 运动控制教师模型训练:在文本到视频基础模型(Wan 2.1,支持1.3B和5B参数版本)上增加运动控制能力,训练能够遵循全局文本提示和局部运动引导的高质量双向视频生成模型,但该模型无法在线推理;(2) 因果学生蒸馏(Self Forcing with Distribution Matching Distillation):将双向教师模型蒸馏为因果学生模型,核心设计包括:(a) 精心设计的滑动窗口因果注意力(sliding-window causal attention)结合注意力汇聚(attention sinks),固定上下文窗口确保O(1)推理成本;(b) 自滚动(self-rollout)训练:在训练中模拟推理时序,通过注意力汇聚和KV缓存滚动正确模拟推理时的外推行为;(c) 块大小(chunk size=3)和采样步数(3步)的精心选择,平衡交互性和质量。硬件加速方面,训练了Tiny VAE(9.84M/56.7M参数)作为快速解码器,比全VAE快13倍,PSNR仅轻微下降(29.27 vs 31.43 for Wan 2.1)。实验支持三种交互方式:轨迹绘制、相机控制和运动迁移。
图注:To build a teacher motion-controlled video model, we extract and randomly sample 2D tracks from the input video and encode them using a lightweight
- 🚀 研究方向迁移:可探索将MotionStream扩展到音频驱动的视频生成(语音口型同步);可研究更大块大小的实时生成以提升质量;可将此框架应用于实时3D场景生成流式系统;可探索边缘设备上的轻量级实时视频生成部署方案。
#11 NeuralRemaster: Phase-Preserving Diffusion for Structure-Aligned Generation
⭐ 推荐 | 评分:
8.0/10| 领域:Image/Video Generation & Translation | arXiv · PDF
作者:Yu Zeng, Charles Ochoa, Mingyuan Zhou, Vishal M. Patel, Vitor Guizilini, Rowan McAllister标签:
Diffusion Models·Phase-Preserving·Frequency Domain·Image-to-Image Translation·Sim-to-Real Transfer一句话总结:提出相位保留扩散(φ-PD),通过在频域中保留输入相位、随机化幅度来实现无需额外参数或架构修改的结构对齐生成。
图注:Unlike prior approaches that modify architectures and add overhead, preserves structure via phase consistency, remaining lightweight and model-agnostic, reflecting that image-conditioned
研究背景与方法
- 研究背景:扩散模型在图像生成领域取得了巨大成功,但标准扩散过程使用高斯噪声同时破坏频域中的幅度和相位分量。信号处理理论表明,相位编码空间结构而幅度编码纹理统计,因此破坏相位会导致空间几何信息丢失。现有的结构对齐生成方法(如ControlNet、T2I-Adapter)通过增加额外模块来注入结构信息,引入了额外的参数和计算开销,使得本应更简单的条件生成任务变得复杂。
- 研究问题:如何在扩散生成过程中保持输入图像的空间结构(几何一致性),同时支持外观的自由变化,且不引入额外的网络结构或参数开销?
- 核心方法:核心方法为相位保留扩散(Phase-Preserving Diffusion,φ-PD):给定输入图像 I,计算其傅里叶变换得到相位谱 φ_I 和幅度谱 A_I;构造结构化噪声时,将高斯噪声的随机幅度 A_ε 与输入相位 φ_I 组合,生成保持输入相位的噪声 ε̂;在扩散训练的前向过程中使用此结构化噪声替代高斯噪声,在测试时以输入相位构造的结构化噪声作为起点进行采样。此外提出频率选择性结构噪声(FSS Noise),通过单一频率截断参数 f_c 在低频处保留输入相位(保结构)、高频处使用纯高斯噪声(允许创意),实现对结构刚性程度的连续控制。该方法无需修改网络架构,与任何DDPM或flow-matching模型兼容,且不引入任何推理时间开销。
图注:Unlike prior approaches, this method preserves structure via phase consistency.
- 🚀 研究方向迁移:可探索将φ-PD应用于视频编辑的时序一致性控制;与ControlNet等显式结构控制方法结合的混合框架;在自动驾驶、医疗影像增强等领域的仿真数据增强应用;以及扩展到3D场景中的结构对齐生成任务。
#12 MultiGO++: Monocular 3D Clothed Human Reconstruction via Geometry-Texture Collaboration
⭐ 推荐 | 评分:
8.0/10| 领域:3D Human Reconstruction | arXiv · PDF
作者:Nanjie Yao, Gangjian Zhang, Wenhao Shen, Jian Shu, Yu Feng, Hao Wang标签:
3D Human Reconstruction·Monocular Reconstruction·Geometry-Texture Collaboration·Implicit Function·3D Avatar一句话总结:提出MultiGO++,通过多源纹理合成、区域感知形状提取和几何-纹理协同双U-Net,显著提升了单目有衣人体三维重建的几何与纹理质量。
图注:Previous SOTA approaches always struggle with recovering the correct human pose, shape, and fine-grained geometry and texture details. For a detailed vie
研究背景与方法
- 研究背景:单目三维有衣人体重建旨在从单张图像生成完整真实的带纹理三维Avatar,是AR/VR、数字娱乐等领域的核心技术。现有方法通常在多视角监督下训练,并依赖预训练网络从单目输入估计几何先验(如SMPL参数)。这些方法面临三大核心限制:训练数据纹理不足、外部几何先验估计不准确、以及单模态监督导致的偏差,导致重建质量次优,尤其在复杂姿态、宽松服装等挑战场景下表现不佳。
- 研究问题:如何在单目输入条件下,同时提升三维有衣人体重建的几何精度和纹理保真度,克服训练数据稀缺、先验估计误差和单模态监督偏差三大瓶颈?
- 核心方法:MultiGO++由三个核心模块组成:(1)多源纹理合成策略:构建了15,000+三维带纹理人体扫描数据,利用商业和合成数据扩充训练集,解决纹理训练数据不足问题;(2)区域感知形状提取模块:对每个身体区域(头部、躯干、四肢等)分别提取并交互特征,提取几何信息;引入傅里叶几何编码器(Fourier Geometry Encoder)来弥合几何模态间的表示差距,实现有效几何学习;(3)几何-纹理协同双重建U-Net:同时利用几何特征和纹理特征,通过双U-Net架构协同精化,生成高保真带纹理三维人体网格。训练使用AdamW优化器(学习率1e-5),损失函数包括MSE、LPIPS(权重2)和mask损失,在8张A800 GPU上约72 GPU小时收敛。
图注:Our framework integrates three core components: Texturally, we employ a multi-source texture synthesis strategy to generate diverse synthetic data for training, along with a
- 🚀 研究方向迁移:可拓展至动态人体重建(加入时序信息)、多人同时重建、衣物物理模拟与重建联合建模;也可将傅里叶几何编码用于提升基于NeRF/Gaussian Splatting的人体表示质量。
#13 F-Actor: Controllable Conversational Behaviour in Full-Duplex Models
⭐ 推荐 | 评分:
7.5/10| 领域:Full-Duplex Conversational Speech Generation | arXiv · PDF
作者:Anonymous Authors标签:
Full-Duplex Speech·Instruction Following·Conversational AI·Speech Language Model·Backchanneling一句话总结:提出首个开源指令跟随全双工对话语音模型F-Actor,通过冻结音频编码器仅微调语言模型,以2000小时数据实现对说话人声音、对话行为(反馈音、打断)、话题和对话发起的可控生成。
图注:Overview of our controllable full-duplex model, which can be prompted to control (i) speaker voice, (ii) conversation topic, (iii) conversational behaviour (e.g., backchanneling and interruptions), an
研究背景与方法
- 研究背景:口语对话系统需要超越准确的语音生成,还需产生自然的对话行为以真正模拟人类交互。现有全双工语音系统(如Moshi等)虽能实现双向实时对话,但极少提供对对话行为(反馈音backchanneling、打断interruption)的细粒度控制,限制了系统的自然性和可用性。此外,现有方法通常依赖大规模预训练和多阶段优化,对计算资源要求极高,难以在学术资源限制下复现。
- 研究问题:如何构建一个可在普通学术资源下高效训练的全双工对话语音模型,支持通过指令控制说话人声音、对话话题、对话行为(反馈音和打断次数)以及对话发起方?
- 核心方法:F-Actor的核心设计是:冻结音频编码器(使用Mimi/NanoCodec等Neural Audio Codec),仅对语言模型部分进行微调,大幅降低训练数据和计算需求(2,000小时数据,4张A100-40GB,46-48小时训练)。采用单阶段训练协议(single-stage training),无需多阶段优化。音频离散化方面支持两种范式:基于RVQ的Mimi编码器和基于FSQ的NanoCodec,后者通过Hydra多头输出层并行预测独立码本索引。提示构建:参考Behavior-SD数据集,构造指令提示指定(1)打断和反馈音次数;(2)对话发起方;(3)对话话题(叙事文本或目标描述)。评估维度包括:UTMOS语音质量分、词错误率(WER)、说话人嵌入一致性(ECAPA-TDNN余弦相似度)、叙事遵循度(Llama-3.1-8B-Instruct作为评判者)、反馈音和打断与提示指定数量的Pearson相关系数。
图注:Full-duplex spoken dialogue system architecture.
- 🚀 研究方向迁移:可探索将F-Actor扩展到多语言全双工对话;与大语言模型agent集成实现更智能的对话策略;以及在具身机器人交互场景中应用可控对话行为的生成。
#14 Revisiting an Old Perspective Projection for Monocular 3D Morphable Models Regression
👍 值得一读 | 评分:
7.0/10| 领域:3D Face Reconstruction | arXiv · PDF
作者:Toby Chong, Ryota Nakajima标签:
3D Morphable Model·Camera Projection·Perspective Distortion·Head-Mounted Camera·Face Reconstruction一句话总结:提出伪透视相机模型,通过在正交投影中引入单一收缩参数rho,有效捕捉近距离人脸的透视畸变,并通过微调提升3DMM回归准确性。
图注:Visualization of the newly introduced shrinkage parameter . We estimate the 3DMM and camera parameters using SMIRK~, which employs orthogonal projection (). We va
研究背景与方法
- 研究背景:三维可变形人脸模型(3DMM)回归是AR/VR和人机交互的基础技术。现有回归方法普遍采用正交投影以规避焦距与物体距离之间的歧义性,这在普通拍摄距离(>50cm)下有效,但在头戴相机(HMC)等极近拍摄场景(15-30cm)下,忽略透视效果会导致明显几何失真:典型表现为鼻子重建偏小,以及面部轮廓出现扩张效应(expanding brain effect)。这一问题在XR设备、专业影视表情捕捉等应用中日益突出。
- 研究问题:如何在保持正交投影稳定性(避免焦距-距离歧义)的前提下,将透视畸变效果引入3DMM回归方法,以改善头戴相机等近距离拍摄场景下的人脸重建质量?
- 核心方法:核心贡献是伪透视相机模型(Pseudo-Perspective Camera Model)。在正交投影公式 u=Sv_x, v=Sv_y 基础上,引入收缩参数rho,修改为:u=Sv_x/(1+rhov_z), v=Sv_y/(1+rhov_z)。当rho=0时退化为正交投影;rho增大时逐渐引入透视效果(近似f=S/rho)。通过反向传播可端到端优化rho。在E_beta编码器上添加线性层+sigmoid激活来回归rho;以松散先验rho_prior(HMC1M取4.0,其他取0.0)引导无监督学习;L2正则化损失权重lambda_p=0.1。还引入鼻部和轮廓区域特殊掩码策略处理歧义区域。构建了HMC1M数据集(约200名演员,15-30cm拍摄距离,共100万张图像)用于微调,并结合MEAD、FFHQ、CelebA。
图注:Visualization of the shrinkage parameter rho in the proposed perspective camera model.
- 🚀 研究方向迁移:可拓展至全身3DMM回归中的透视效果建模;与神经渲染结合实现更精细的自监督微调;也可探索将rho参数扩展为动态参数,用于视频流中的实时焦距估计。
#15 EA-Swin: An Embedding-Agnostic Swin Transformer for AI-Generated Video Detection
⭐ 推荐 | 评分:
7.5/10| 领域:AI-Generated Video Detection / Deepfake Detection | arXiv · PDF
作者:Martin (Hung) Mai, Loi Dinh, Duc Hai Nguyen, Dat Do, Luong Doan, Khanh Nguyen Quoc, Huan Vu, % Phong Ho, Naeem Ul Islam标签:
AI-Generated Video Detection·Swin Transformer·Spatiotemporal Modeling·Deepfake Detection·Video Foundation Models一句话总结:提出EA-Swin(嵌入无关Swin Transformer),通过在预训练视频嵌入空间建模时空依赖来检测AI生成视频,在主流生成器上达到0.97-0.99的检测精度。
图注:Top: Recent generators produce high-quality visuals and realistic motion, closely resembling real videos. Bottom: Earlier models show clear
研究背景与方法
- 研究背景:以Sora2、Veo3为代表的基础视频生成模型已能生成高度逼真的合成视频,极大增加了AI生成内容滥用的风险。现有检测方法存在三类局限:依赖浅层嵌入轨迹(如简单计算帧间嵌入差值)的方法随生成质量提升而失效;基于图像的检测器无法捕捉视频的时序动态;基于多模态大语言模型(MLLM)的方法计算代价高昂且主要依赖语义推理而非生成过程特征。同时,现有基准数据集往往受限于过时的生成器或生成器覆盖不足,难以支持严格的跨分布评估。
- 研究问题:如何构建一个高效、可扩展的AI生成视频检测框架,能够在表示空间(而非像素空间)中建模真实视频与合成视频的时空依赖差异,并在多种未见生成器上保持强泛化能力?
- 核心方法:EA-Swin是一个嵌入无关的时空检测头,直接在冻结的预训练视频编码器(如ViT-style patch encoder)输出的嵌入上操作。核心设计为分解式窗口注意力(factorized windowed attention):借鉴Swin Transformer的分层移位窗口注意力机制,分别在时间维度和空间维度上建模注意力,避免全局注意力的计算复杂度。通过将检测与特定编码器解耦(视频编码器冻结),框架可直接兼容通用ViT-style编码器。同时构建了EA-Video数据集:共约130K视频,涵盖多个商业和开源生成器(包括Sora2-like、Veo3-like等高质量生成器),设有未见生成器(unseen-generator)分割用于跨分布评估;收集自AIGVD、VidProM、GenBusterX等多个数据源,以及新采集的样本。
图注:Architecture overview of the proposed method.
- 🚀 研究方向迁移:可探索将EA-Swin扩展为支持多模态(视频+音频)检测;在表示空间进行主动对抗训练以提升对未知生成器的鲁棒性;以及将检测头设计为可持续更新(continual learning)以适应新出现的生成器。
#16 Accelerating Text-to-Video Generation with Calibrated Sparse Attention
⭐ 推荐 | 评分:
7.5/10| 领域:Video Generation | arXiv · PDF
作者:Shai Yehezkel, Yaniv Nemcovsky标签:
Sparse Attention·Video Diffusion Models·Inference Acceleration·Training-Free Optimization·FlashAttention一句话总结:CalibAtt通过离线校准识别视频扩散Transformer中稳定的块级稀疏注意力模式,实现无训练的高效推理加速,在Wan 2.1 14B等模型上最高获得1.58倍端到端加速。
图注:Sparsity vs.\ relative error. [width=]images/anchor_rows/repeat_sweep_metrics_plot_tradeoff.pdf \
研究背景与方法
- 研究背景:基于Transformer的视频扩散模型(如Wan 2.1、Mochi 1)在生成高质量视频方面表现卓越,但其时空注意力机制的计算复杂度与序列长度呈二次方关系,导致推理速度极慢。现有加速方法要么需要对模型进行微调(限制了适用范围),要么在推理时动态估计稀疏模式(引入额外开销),要么采用固定的衰减掩码(无法适应不同层/头/时间步的差异化注意力模式)。
- 研究问题:如何在不重新训练模型的前提下,高效地为视频扩散Transformer的每一层、每个注意力头、每个扩散时间步自动确定并利用稳定的稀疏注意力模式,从而实现硬件友好的推理加速?
- 核心方法:CalibAtt的核心是离线校准阶段:使用少量代表性样本(少至1个视频)对目标模型进行一次前向传播,在FlashAttention块级别收集每一层、每个注意力头、每个扩散时间步的后softmax注意力矩阵P的统计信息,识别出两类稳定的跨输入模式:(1) 稀疏掩码——标记哪些块的注意力分数始终可忽略不计可以跳过;(2) 重复查询——某些查询块的注意力输出与其他查询块几乎相同(尤其在去噪后期的低噪声时间步),可以通过重复使用已计算的输出来跳过重复计算。校准完成后,这些模式被编译为每个(层,头,时间步)组合对应的优化注意力操作。推理时,系统基于预编译掩码执行块级稀疏注意力,与FlashAttention3内核集成实现硬件高效的计算跳过,对于被识别为重复的查询则直接复用已有输出。这种方式避免了推理时的任何额外开销,同时通过精准的模型级校准超越了使用固定先验掩码的方法。
图注:Offline calibration per timestep/layer/head [b]0.277
- 🚀 研究方向迁移:未来可探索:(1) 将校准机制扩展到交叉注意力(cross-attention)层以加速文本条件注意力;(2) 与其他推理优化技术(如缓存机制、量化)的结合;(3) 将校准思路应用于长上下文LLM的KV cache压缩;(4) 开发自适应校准更新策略以处理分布漂移。
#17 A Simple Baseline for Unifying Understanding, Generation, and Editing via Vanilla Next-token Prediction
👍 值得一读 | 评分:
7.0/10| 领域:Unified Understanding and Generation | arXiv · PDF
作者:Jie Zhu, Hanghang Ma, Jia Wang, Yayong Guan, Yanbing Zeng, Lishuai Gao标签:
Autoregressive Model·Next-Token Prediction·Multi-Modal Understanding·Image Generation·Image Editing一句话总结:Wallaroo基于Qwen2.5 VL,通过纯自回归下一token预测范式和四阶段训练策略,将多模态理解、图像生成与图像编辑统一在一个简洁的基线模型中,支持多分辨率和中英双语。
图注:Some text-to-image generation showcases of our Wallaroo. % -0.25in
研究背景与方法
- 研究背景:统一多模态理解与生成是迈向通用人工智能的重要方向,当前主流方法分为三类:(1) 将理解模型作为扩散生成的增强编码器(如OmniGen2),存在单向信息流限制;(2) 在Transformer中并行集成自回归理解和扩散生成(如Transfusion、Bagel),但扩散噪声表示降低了信息交互效率;(3) 基于自回归下一token预测的统一模型(如Chameleon、Janus系列),结构简洁但通常面临视觉tokenizer质量不足、或未同时支持编辑任务等问题。
- 研究问题:如何基于纯自回归next-token prediction范式,在尽量少修改现有多模态理解模型的前提下,同时支持多模态理解、图像生成和图像编辑三类任务,并实现多分辨率输入输出和双语支持?
- 核心方法:Wallaroo以Qwen2.5 VL为骨干网络,遵循极简主义原则进行最少修改:(1) 架构设计:视觉编码解耦为两条路径——理解路径沿用Qwen2.5 VL内置的NaViT编码器,生成路径额外引入LlamaGen的VQ tokenizer将图像离散化为ID序列,通过各自的MLP适配器对齐到Transformer维度;编辑任务则同时利用NaViT(提供语义表示)和VQ encoder(提供低级细节),用独立的编辑MLP适配器和编辑头处理;(2) 四阶段训练策略:Stage 1冻结骨干只训练生成MLP适配器和生成头做初步对齐;Stage 2解冻全模型(除NaViT和VQ tokenizer)进行理解与生成联合预训练;Stage 3将图像尺寸从384扩展到512并进行多分辨率适配(通过
特殊token指定目标尺寸, token标记行结束);Stage 4在三个任务上联合精调;(3) 训练目标:纯next-token prediction交叉熵损失,三个任务权重均为1,推理时对生成任务使用CFG(γ=3)。
图注:Illustration of our Wallaroo. We decouple visual encoding into separate pathways for visual understanding and image generation. For editing, we integrate two complementary types of visual representati
- 🚀 研究方向迁移:未来可探索:(1) 扩展到视频理解与生成的统一;(2) 引入更强的视觉tokenizer(如连续VAE+离散hybrid)以提升生成质量;(3) 探索编辑任务在解纠缠表示学习中的作用;(4) 在更大规模数据和模型参数下验证该极简范式的扩展性。
#18 True Self-Supervised Novel View Synthesis is Transferable
⭐ 推荐 | 评分:
8.0/10| 领域:Novel View Synthesis | arXiv · PDF
作者:Anonymous Authors标签:
Novel View Synthesis·Self-Supervised Learning·Transferability·Stereo-Monocular Model·Latent Pose Representation一句话总结:XFactor提出「可迁移性」作为真实NVS的核心判别准则,通过立体单目模型与可迁移性训练目标(配合姿态保持数据增强),首次实现完全无几何归纳偏置的自监督真实新视角合成。
图注:We evaluate the robustness of VGGT~ and COLMAP~ oracles against visual
研究背景与方法
- 研究背景:新视角合成(NVS)是计算机视觉的核心问题,监督方法(如LVSM、pixelSplat)依赖COLMAP等oracle提供精确相机位姿,限制了对无标注视频的适用性。自监督NVS方法(如RayZer、RUST)试图无需位姿标注地端到端学习位姿估计和渲染,但现有评估体系仅关注自编码重建质量,忽略了一个根本性问题:学到的「位姿」表示是否真正可控、可跨场景迁移?研究发现RayZer和RUST的位姿预测本质上是编码「如何在上下文视图间插值」,而非真实的相机姿态,导致在不同场景间完全失去可迁移性。
- 研究问题:如何设计一个完全自监督的NVS模型,使其学到的潜在位姿表示具备真正的可迁移性——即从序列A提取的位姿能够正确渲染序列B中相同相机轨迹下的目标视图——而不依赖任何几何先验、SE(3)参数化或外部位姿预测器?
- 核心方法:XFactor(Transferable[X] Latent Factorization)由三个核心设计组成:(1) 立体单目模型(Stereo-Monocular Model):将输入简化为单对图像(I1作为上下文,I2作为目标),位姿编码器PoseEnc从(I1,I2)对中提取相对位姿潜变量Z2,渲染器Render仅以单张图像I1和Z2为条件重建I2。这种设计强迫渲染器无法通过多视图插值取巧,必须进行真正的外推推理;(2) 可迁移性训练目标:给定两对具有相同相对相机运动但不同场景内容的图像对(I1A,I2A)和(I1B,I2B),要求从对A提取的位姿潜变量能够在场景B中渲染出正确的目标视图:L = d_I(I2B, Render[I1B, PoseEnc[I1A, I2A]])。这直接将可迁移性作为优化目标;(3) 姿态保持数据增强:对任意视频帧对随机生成两个等面积互补掩码,结合颜色抖动和模糊,生成共享相同相机运动但几乎无像素重叠的图像对,为可迁移性目标提供自监督训练信号,无需任何外部位姿预测器。PoseEnc和Render均以多视图ViT实现,训练损失为L1范数与感知损失(LPIPS)的线性组合。
图注:The method combines a stereo-monocular model with a transferability objective.
- 🚀 研究方向迁移:未来方向包括:(1) 扩展到多视图输入以提升重建质量;(2) 将可迁移性训练框架应用于动态场景和视频理解;(3) 探索潜在位姿作为轻量级相机参数的应用(替代COLMAP);(4) 与生成模型结合实现条件化新视角生成。
#19 Gaussian Wardrobe: Compositional 3D Gaussian Avatars for Free-Form Virtual Try-On
⭐ 推荐 | 评分:
7.5/10| 领域:3D Avatar Generation / Virtual Try-On | arXiv · PDF
作者:Zhiyi Chen, Hsuan-I Ho, Tianjian Jiang, Jie Song, Manuel Kaufmann, Chen Guo, HKUST(GZ) HKUST标签:
3D Gaussian Splatting·Neural Avatars·Virtual Try-On·Compositional Representation·Free-Form Garments一句话总结:Gaussian Wardrobe将人体avatar分解为体型无关的多层3D高斯服装表示,支持从多视角视频中学习各层服装的动态行为,实现跨人体的自由服装迁移和虚拟试穿。
图注:We rendered segmentation masks of garment layers to visualize the impact of each regularization term. The evaluation shows that our full
研究背景与方法
- 研究背景:基于3D高斯溅射(3DGS)的神经人体avatar技术(如Animatable Gaussians)在新姿态合成方面已取得显著进展,但现有方法普遍将人体与服装视为不可分割的整体进行建模。这一范式无法单独捕捉复杂自由形态服装(如长裙、宽松外套)的动态行为,且模板中编码了主体特定的体型信息(SMPL-X形状参数β),导致学到的服装表示与特定人体绑定,无法跨主体复用,严重限制了数字虚拟衣橱的实用性。
- 研究问题:如何从多视角视频中学习可组合的神经人体avatar,使每层服装(上装/下装/外套)的3D高斯表示与主体体型解耦,从而实现在保持人体identity不变的前提下,将任意服装层从一个人自由迁移到另一个人?
- 核心方法:Gaussian Wardrobe以Animatable Gaussians为基础进行组合扩展:(1) 体型无关模板:将原始SMPL-X形态模板通过去除形状混合形状(beta相关的blendshape偏移量)变换到零形状规范空间,消除主体特定的体型信息,利用Fast-SNARF的体素化策略将SMPL-X混合形状偏移扩散到64^3体素网格;(2) 多层组合分割:对规范模板进行3D分割,划分为上装(Mu)、下装(Ml)、可选外套(Mo)和体躯(Mb)层,每层独立拥有自己的坐标图、姿态图和U-Net网络;(3) 分层3D高斯预测:各层U-Net Fl以坐标图Cl(规范位置)和姿态图Pl(θm)(骨骼驱动后的变形位置)为输入,预测对应的高斯参数图(14维:位置偏移、旋转、不透明度、缩放、颜色);(4) 形变与合成渲染:对每个高斯基元从规范空间变形到目标姿态空间(先恢复体型混合形状,再LBS变形),复合所有层的高斯后通过splat光栅化器渲染RGB图像和分割掩码;(5) 损失函数:光度损失(L1+SSIM+LPIPS+人脸LPIPS)+ 分割损失(多类别掩码对齐+体躯模板约束)+ 正则化损失(穿透惩罚铰链损失+偏移平滑+体躯不透明度约束);(6) 穿透感知渲染:推理时通过轮廓检测算法实时检测并修正层间穿透像素。
图注:digitalizes compositional neural avatars from multi-view videos. Our pipeline consists of two major components: (left) a compositional Gaussian representation and (right
- 🚀 研究方向迁移:未来可探索:(1) 扩展到单目视频输入以降低数据采集门槛;(2) 结合生成模型实现从文本描述创建新服装并添加到衣橱;(3) 将分层建模扩展到动物毛发、人体饰品等更复杂的附属物;(4) 开发交互式多人虚拟试穿系统。
#20 RealWonder: Real-Time Physical Action-Conditioned Video Generation
⭐ 推荐 | 评分:
8.0/10| 领域:Video Generation / Physics Simulation | arXiv · PDF
作者:Wei Liu, Ziyu Chen, Zizhang Li, Yue Wang, Hong-Xing Yu, Jiajun Wu标签:
Real-Time Video Generation·Physics Simulation·Action-Conditioned Generation·Optical Flow·Diffusion Distillation一句话总结:RealWonder通过将物理仿真作为3D动作与视频生成模型之间的中间桥梁,结合光流条件蒸馏和因果流式生成,首次实现480x832分辨率13.2 FPS的实时物理动作条件视频生成。
图注:() Given a single image and a sequence of actions as input, we first reconstruct the 3D scene as point clouds, () estimate material for the obj
研究背景与方法
- 研究背景:现有视频生成模型在生成视觉质量和多样性上取得了巨大进步,但无法理解3D物理动作(如施加力、机械臂操控)的因果效应——它们缺乏对动作如何影响3D场景结构的理解。将3D物理动作直接作为视频生成的条件信号面临两大挑战:连续力/运动学空间与像素/潜变量空间之间存在根本性语义鸿沟;且动作-视频训练对极为稀缺。此外,现有视频扩散模型通常需要50步去噪且需要并行处理完整帧序列,无法满足实时交互的时延要求。
- 研究问题:如何设计一个从单张图像出发的实时视频生成系统,使其能够响应连续的3D物理动作(力、机器人关节操控、相机运动),并在480×832分辨率下以交互帧率(>10 FPS)生成物理上合理的视频流?
- 核心方法:RealWonder由三个流水线阶段组成:(1) 单图像3D场景重建:将场景分为静态背景(点云)和动态物体(点云+完整3D网格),用VLM分类每个物体的材质类型(刚体、弹性、布料、烟雾、液体、颗粒)并估计物理参数;(2) 物理仿真作为中间桥梁:采用Genesis仿真器,针对不同材质使用专用求解器——Shape Matching(刚体碰撞)、Position-Based Dynamics(弹性体/布料/烟雾)、Material Point Method(液体/颗粒),机器人动作通过逆运动学转化为关节力矩驱动Franka模型;仿真输出通过相机投影计算光流F_t,以及点云光栅化生成粗糙RGB预览V_tilde;(3) 实时条件视频生成:两阶段训练——先基于VideoXFun wan2.1-1.3B冻结所有权重,注入LoRA(rank=2048)训练光流条件(通过噪声warp实现流控制,无需额外条件网络),再通过DMD(分布匹配蒸馏)+Self Forcing范式将双向教师蒸馏为4步因果学生模型;推理时通过SDEdit(从第3步而非第4步开始去噪,混入粗糙RGB预览编码的潜变量)同时利用光流(运动精度)和RGB预览(结构线索)双重条件;通过存储RoPE前的KV cache和注意力sink实现长序列稳定的流式生成。
图注:Overview of the approach for physically-plausible video generation.
- 🚀 研究方向迁移:未来方向包括:(1) 扩展到非刚性变形体(人体动作、表情)的物理精确仿真;(2) 将物理仿真反向用于从视频中估计物理参数(inverse simulation);(3) 开发多智能体协同物理交互的生成;(4) 将RealWonder作为机器人sim-to-real迁移的数据生成工具。