MSMD | SIGGRAPH 2025 | Paper Reading
Model See Model Do: Speech-Driven Facial Animation with Style Control
当前的 3D Taling Head Generation 的SOTA文章,主要改进 SIGGRAPH 2024 DiffposeTalk中对风格生成的局限性问题。
摘要
现有方法在实现精确的口型同步和生成基本的情感表达已经取得了极大的进步,但是在 捕获和有效地迁移微妙的表示风格 面临挑战。
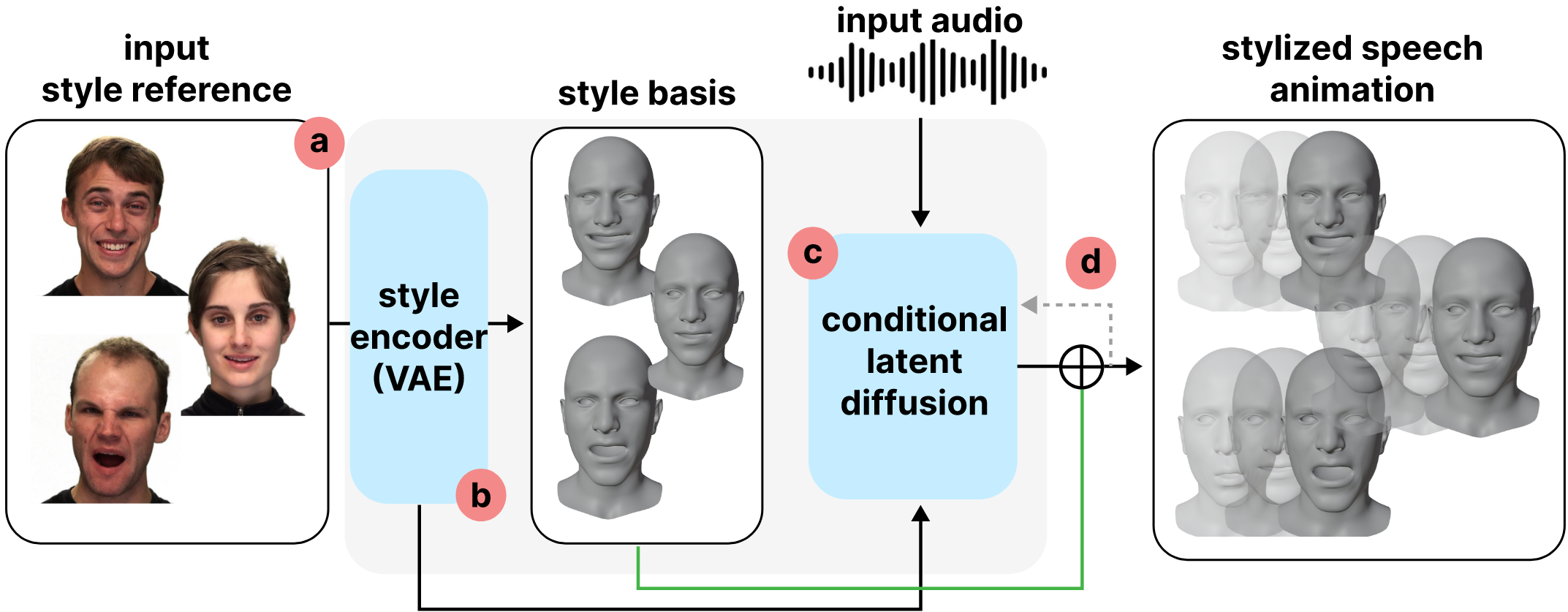
为了解决精确复现参考风格的挑战,作者引入了一种称为风格基的新颖条件机制,能够 从参考风格中提取关键姿势并进一步地指导扩散生成过程 实现风格拟合而无需损害口型同步质量。
研究背景
Open Problem
除了口型同步性问题,生成具有facial motions的talking head 能够让人更加信服,但是facial movements 仅与音频具有弱相关关系,例如睫毛运动、额头以及嘴型张开的大小。
这指向了同一个研究问题,生成可控的facial motions仍然是一个需要探索的问题。
现有方法
最近的研究工作一种是在Motion生成过程中添加 emotion labels以及text。但实际上,说话表现会受到混合因素的影响(角色特征、情绪基调或人物身份),这导致了难以通过离散化的labels标注或文本来注解描述,因为很难说清楚影响因素。另外一种方式是,直接从实例中学习(example-based),不管受到什么因素影响,直接从实例中学习风格化生成。
Example-based Method
DiffPoseTalk首次在音频驱动的facial animations中采用example-based风格控制,利用对比损失来单独学习风格。这种方法的限制性存在于,在单独的步骤中利用对比损失,风格编码与主要的生成任务保持独立,难以学习到由音频内容确定的人脸运动(虽然是弱相关关系)以及不同表演中有所差异的风格选择。此外,对比学习框架会将非匹配的样本当成同等不相似的负样本,例如,两个未匹配的 angry表情会被分离到与 angry和 happy一样远的距离。
目的:确保生成的facial motion 同时匹配style 和audio content
作者延续 example-based 类方法,将 expressive speech motion 分解为两个互补的组成部分:
- 一次富有表现力的演讲中,可以将其分为时不变表情和运动动态流。
- Time-invariant expressions: 时间不变的表情主要捕获在整个说话过程中全局不变的表情,例如眯眼睛或皱眉头,主要是设定的风格影响;
- Motion dynamics: 运动动态对应于直接和因素内容相关的部分,捕获说话者发音的方式,主要受音频影响。
核心贡献
- 提出了一个基于实例的音频驱动的人脸运动生成框架,能够捕获参考风格的音频特征,精确保留细腻的风格。
- 提出了 style basis 用于基于扩散模型的人脸运动条件生成。
研究动机
作者采访了五位游戏公司的专业动画师,关于现在的研究方法进行讨论,认可了改进自动生成人脸动画工具的必要性,以及现有驱动方法与现代的人脸捕获技术仍然存在较大差距。
驱动生成仍然集中在如何增加生成的可控性,在 talking head 中表现为生成可控的风格表现,具有两种应用场景:
- 低等级动画:游戏序列
低等级动画生成,更希望有完全自动化的解决方案,可以在控制生成上花费最小的时间,例如希望提供一个标签控制风格生成。 - 中等级动画:脚本序列
中等级动画侧重于以交互式的方式具有更多控制和生成,从一个初始的自动生成的动画出发,然后采用细粒度控制进行更新。
Example-based 方法认为采用预先定义的视频可以作为一个标签,增强可控生成而不需要重新训练模型,对于中等级动画则可以通过选择特定情感细微差别或表达难以描述的风格来提供细粒度控制。
研究方法
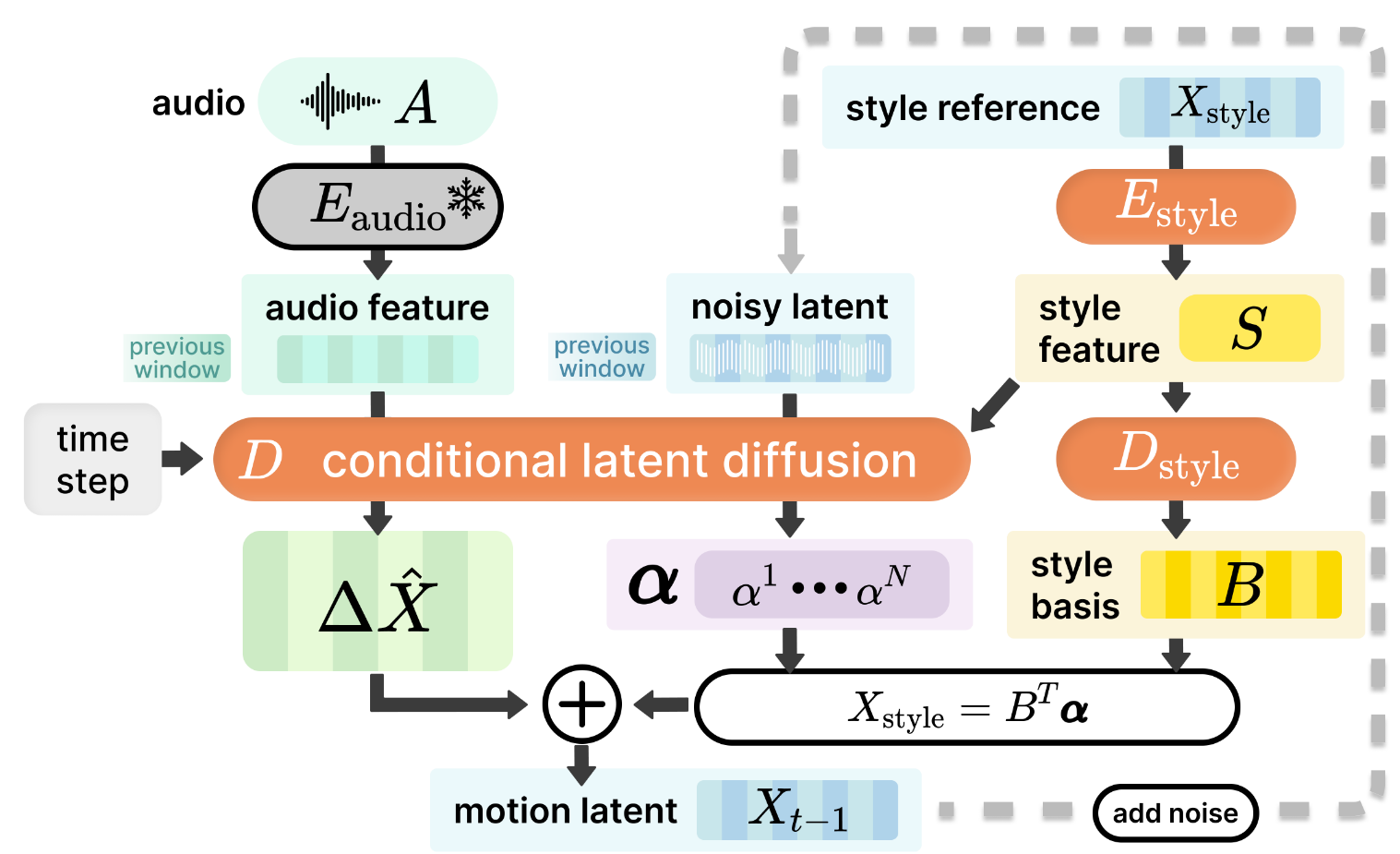
| 说明 | 符号 |
|---|---|
| 输入音频序列 | $A$ |
| 可选的 style 序列 | $X_{\text{style}} = [x^1, \cdots, x^M]$ |
| 新的 motion 序列 | $\hat{X}_0 = [x^1, \cdots, x^N]$ |
| 时不变 style feature | $S = E_{\text{style}}(X_{\text{style}})$ |
| Style 基向量 | $B = [b^1, \cdots, b^K] = D_{\text{style}}(S)$ |
| Primary motion | $\Delta \hat{X}$ |
| Style modulation signal 基系数 | $\alpha$ |
Loss Function
重建损失
$$ \mathcal{L}_{\text{simple}} = \mathbb{E}_{t \sim \mathcal{U}[1, T], X_0, C \sim q(X_0, C)} \left[ \|X_0 - \mathcal{M}(X_t, t, C)\|^2 \right]. $$速度损失
$$ \begin{align} \mathcal{L}_{\text{vel}} &= \| (\mathbf{X}_{N_p+1:N_w} - \mathbf{X}_{N_p:N_w-1}) - (\hat{\mathbf{X}}_{N_p+1:N_w} - \hat{\mathbf{X}}_{N_p:N_w-1}) \|^2. \end{align} $$平滑损失
$$ \mathcal{L}_{\text{smooth}} = \| \hat{\mathbf{X}}_{N_p+2:N_w} - \hat{\mathbf{X}}_{N_p+1:N_w-1} + \hat{\mathbf{X}}_{N_p:N_w-2} \|^2. $$MSMD | SIGGRAPH 2025 | Paper Reading
