Screening, Rectifying, and Re-Screening: A Unified Framework for Tuning Vision-Language Models with Noisy Labels
前言
2024年忙碌了一年的文章,终于成功被 IJCAI 2025 接收,作为第一次投稿的科研小白,也能够开始步入科研的世界。
致谢
项目汇总
较为完整且详细的探究历程,可以转至文章:SRRS 研究方法的探索历程
完整的项目文档材料记录:One Drive
项目前身
在2024年这个项目基础上已经做过了诸多地尝试,较为完整地可以见如下文章,但由于对问题理解不深刻导致方法没有起到太大的作用(需要改进)。
- Double Prompt Learners: Classifier and Discriminator Mechanisms for Noisy Label Learning
- Robust Similarity from Vision-Language Models for Learning with Noisy Labels
研究背景
自大规模的视觉语言模型出现以及Fine-tuning这种研究范式的兴起,在对预训练模型做微调的过程中,也将会面临传统机器学习中一个经典的半监督学习问题——噪声标签学习(Learning with Noisy Labels,LNL)。从 CoOP首次提出,将文本提示词改为 Prompt Learner 大大地提高了 Prompt Engineer 的效率和实现更高的结果。但在下游任务中通过少量样本 Fine-tuning 文本提示词,由于大规模预训练模型的强大表示能力,对 Noisy Labels 进行学习将会受到更严重的影响。
因此,JoAPR 工作首次提出了Robust Prompt Learning(RPL)的研究方向,旨在通过通过各种方法提高提示学习在噪声数据集上的鲁棒性,只要有文本/图像提示学习器,就可以通过这种范式提高Fine-tuning的鲁棒性。显然这是一个不同于传统噪声标签学习的方法,主要有以下几点区别:
- 面向模型不同:传统研究方法主要是解决不同DNN或其他模型的LNL问题,而 RPL 目前主要解决视觉语言模型CLIP的LNL问题,选定的CLIP模型能够提供强大的先验知识,在LNL问题上即是优势(可以有效地微调),但也存在劣势(易于学习到错误的标签);
- 研究目标不同:RPL是传统LNL的一个子集,不像传统LNL仅需要设计模型鲁棒性学习流程,RPL需要额外针对文本提示学习器进行各种各样的处理以确保视觉语言模型的鲁棒性学习流程。
- 样本学习:RPL主要是在 few-shots dataset 上进行 fine-tuning,传统 LNL可以在大量的数据集上直接学习,这也增加了 RPL 任务的难度。
本篇工作主要是延续 JoAPR 旨在解决 RPL 问题,从解决模型自我确认偏差出发,提出了一个 multi-stage 的综合pipline。
研究动机
“self bias” 是LNL中一个比较常见的问题,在 RPL 中由于全程都是在 fine-tuning CLIP,JoAPR中也是根据 CLIP 的预测损失,通过小损失机制来区分干净和噪声样本。
对 prompt learning 的 CLIP 而言,依据模型 online learning 的预测来对样本进行评估,会导致模型依据上一次迭代时学习到的知识来划分当前迭代的样本集,一开始学到错误的知识时,那么其预测作为评估依据就会有很大的误差。
这种循环式的自我确认,导致 online learning 模式在面对复杂和高质量噪声时非常容易出现过拟合到噪声标签上。
一个很好的解决办法是,构造不同的 prompt learner 相互监督避免单一 online learning 模型偏向某个特定的方向,以及对生成的伪标签进行质量评估,因此我们提出了一个 Multi-stage 的方法,保证了prompt learners 尽可能生成可靠的伪标签,并利用 offline learning 模型进行伪标签质量评估。
最最开始写的一个 Motivation 如下所示:
方法

如上图所示,通过构造一个宏观的类别文本提示学习器以及一个微观的类别特征提示学习器,能够通过 JS 散度计算相似度以约束输出一致性的预测,能够为标签翻新提供鲁棒性的损失分布。
经过实验的发现,对于噪声率从简单的 12.5% simflip 到复杂的 75% pairflip,诸如以往方法将数据集划分为干净和噪声子样本集,这是一个非常困难的事情,因为无法做到真正地将样本全部区分开来。为了简化并有效地筛选样本,我首次地将噪声数据集以及样本损失置信水平划分出三个子集:clean, noisy and ambiguous。这意味着,只有非常干净的样本划分到clean subset,并保留原始标签;非常错误的样本划分到 noisy subset 标签被直接替换为模型预测的伪标签;中间比较混淆的样本,通过结合样本划分置信度对原始标签和预测伪标签进行线性加权,得到介于二者之间的鲁棒性伪标签。
翻新的样本标签,并不能够完全摆脱 self bias 的影响,只是想必原始标签变得更加鲁棒了,但进一步地需要评估伪标签的质量。在此为了简化,直接利用另一个预训练的视觉语言模型 BLIP 对预测的标签和对应的样本进行图文匹配,并将得到的匹配相似度作为伪标签质量评估分数。
对高质量标签组,则可以直接进行样本学习;对低质量标签组,我提出了基于 Mixup 的混合增强策略,通过融入高质量标签组进一步增强低质量标签组的可靠度,这确保了最终模型学习时,既没有丢失任何样本,反而大大地提高了标签的可靠性。
在此提一句,最后我做的框架图如下所示,后续基于此确定了最后的版本:

探究历程
在此记录一下整个项目的探索历程,由于个人喜好铅笔做 mind map,字迹稍微有些不清楚,可以进行缩放查阅。
Well-designed Mindmap 总是一步一步地推进并设计出来的,确实没有捷径而言。
- 首先是对参考文章 JoCOR 的分析

- 当时开始提出利用 BLIP 做质量评估的初步思路图

- 对划分为 clean noisy, ambiguous 三个子集的概率分布分析
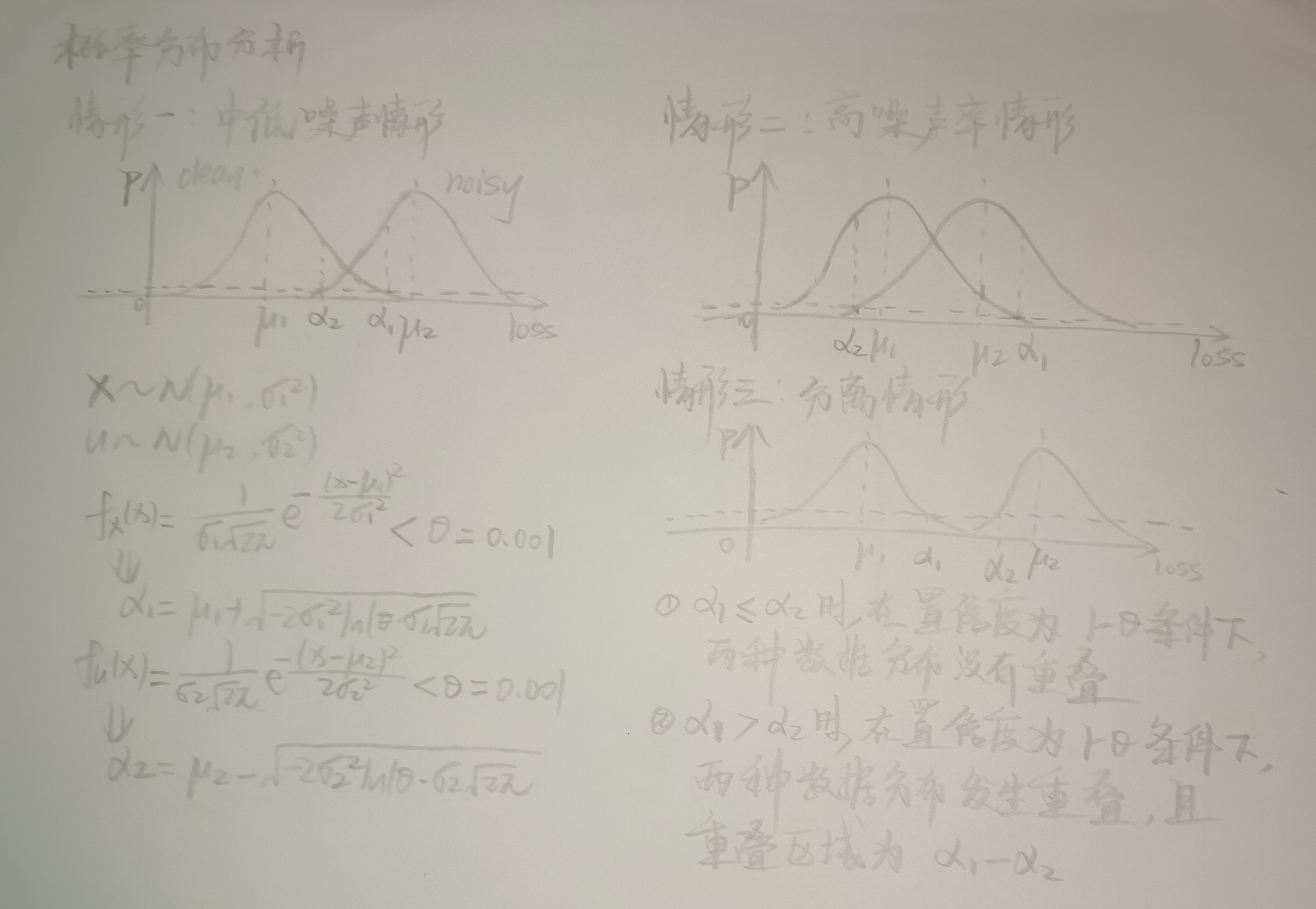
- 当时也曾考虑过对每个样本构造多条提示学习器,但由于增大了学习强度还收效较小,遂没有采用

- 整个框架的流程分析图
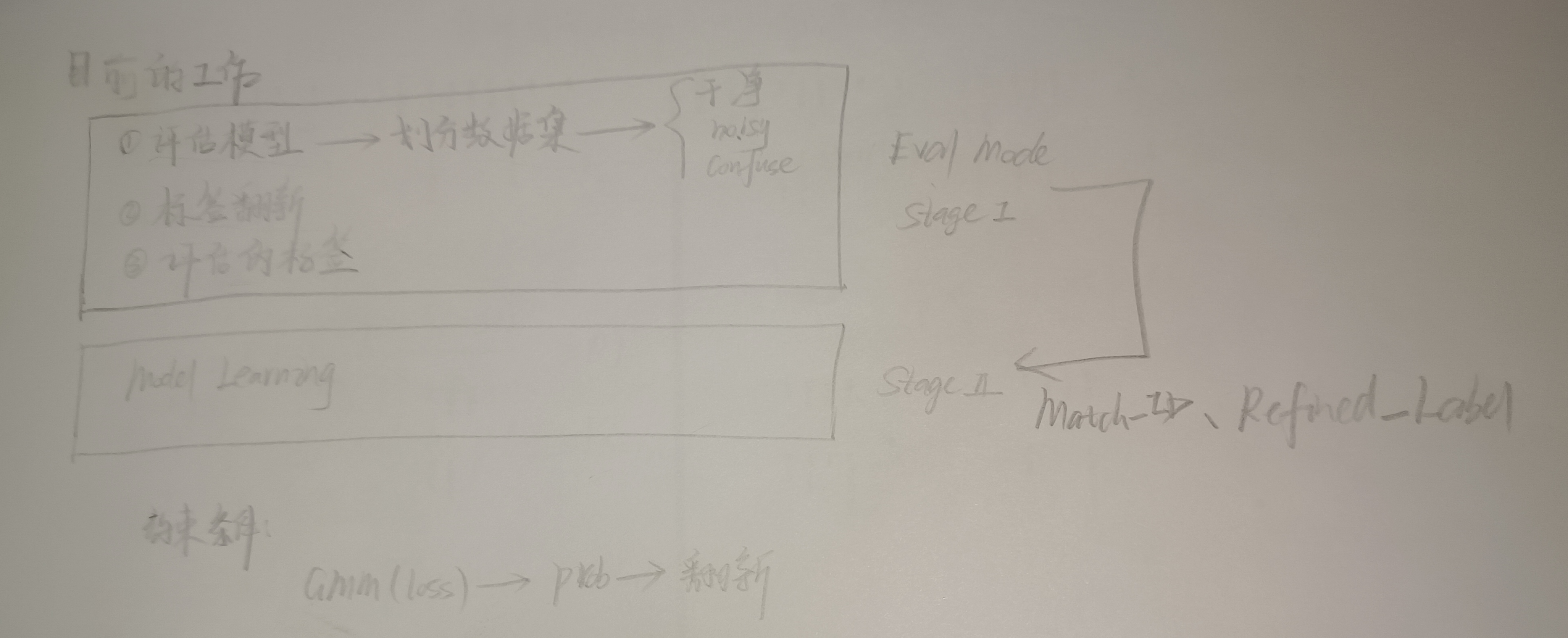
- 最初的雏形思路,对于混淆的样本集选择 BLIP 进行评估
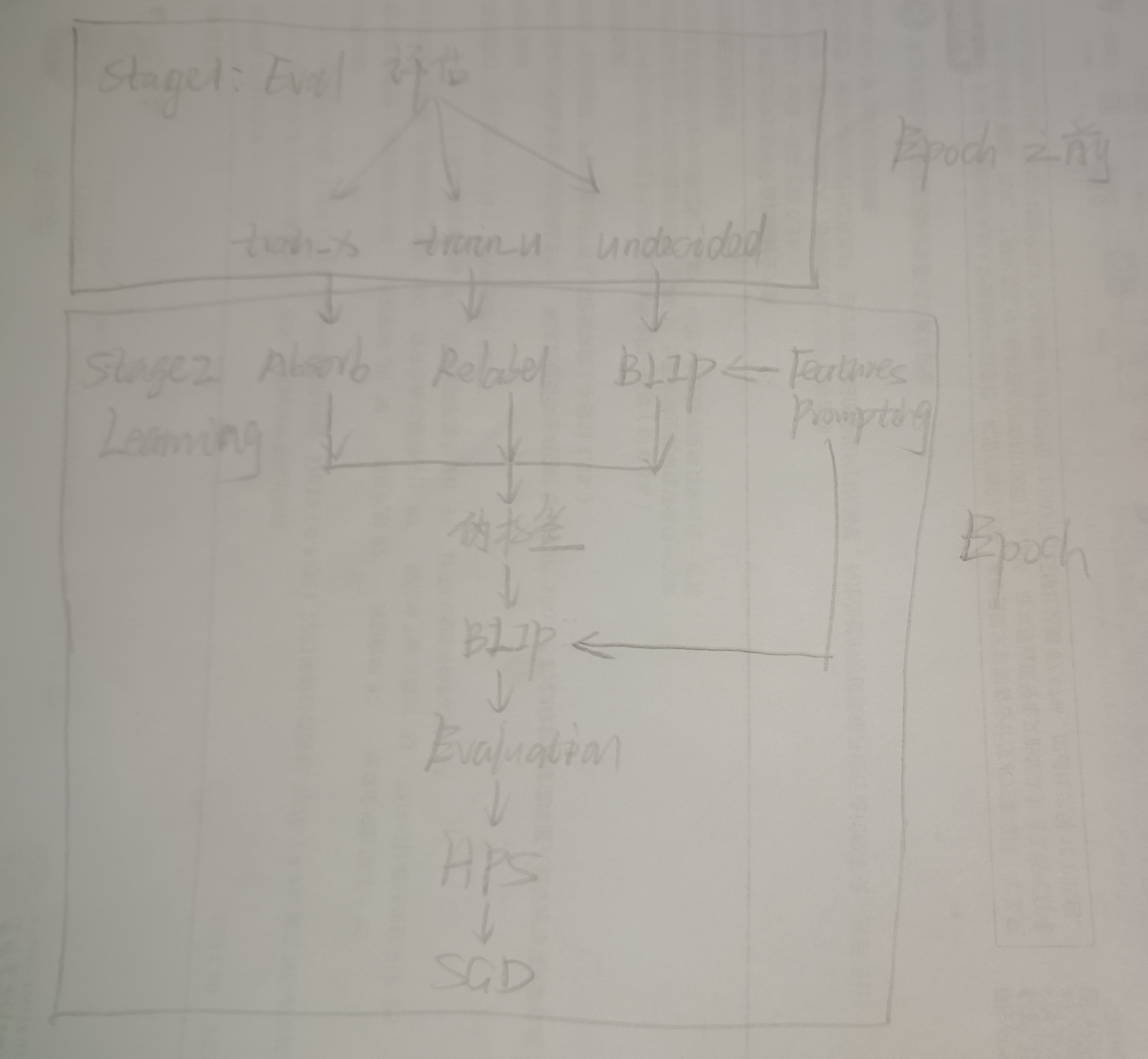
- 对选择的最后思路图的详细分析

- 当时对实验结果验证的一小部分残留笔迹

不足之处
尽管综合来讲,SRRS 取得了较好的结果,在缓解噪声标签的影响中起到了对数据集筛选、翻新并验证的处理流程,但是其中的部分组件仍然需要值得深入探究,更多地面向通用多模态模型(文本提示学习、图像提示学习)等实现鲁棒性效果。
Tricks
实际上,在众多数据集包含着各种水平的噪声上实现强大的鲁棒性是极其困难的,这里也引发了我们关于噪声标签学习的争议。
特征提示学习
功能描述
通过引入各个类别的独有特征进行提示学习,一方面起到增加模型微调的适应能力,对数据集具备更强大的表示(拟合)能力,另一方面是当作一个先验知识,增大类别之间的差异性,细化通用的类别提示学习(a photo of a <cls>),似乎直觉上符合:通用类别提示旨在整体上判断图像中的物体是什么类别,特征提示旨在对此确认,结合先验的类比特征,细致地验证通用类别提示是否判断错误。在设计的损失函数约束下,两个类别特征提示词有望能够实现统一的预测输出,相互学习以实现宏观与微观上的结合。
现有缺陷
- Generation
对于特征提示,目前的做法仅仅是简单地利用 GPT-3.5 生成各个类别的特征提示词,准确性比较依赖于 GPT 的先验知识,以a photo of a <cls>, which has {features}.模板生成的提示词如下所示。features of classes 1
2
3
4
5"face": "which has human facial features including eyes nose mouth and overall expression features",
"leopard": "which has spotted big cat with sleek fur and powerful muscular build features",
"motorbike": "which has two-wheeled vehicle with engine handlebars and distinctive design elements features",
"accordion": "which has musical instrument with bellows and keys producing rich melodic sounds features",
"airplane": "which has aerial vehicle with wings engines and streamlined body for flight features"
怎样获取更加准确地每个类别的特征提示词,有待考量。
- Finetuning
对于一个类别特征提示词,a photo of a <cls>, which has {features}. 应当微调哪一个部分,features 需不需要学习等,目前的做法是直接保留了 features 作为类别监督的一部分,以增大类别差异性。
噪声数据集划分
灵活性
clean, noisy and ambiguous 的划分,是主动地根据小损失样本机制,将其分为了直观且易处理的样本子集。但是置信水平的设置仍然是一个比较艰难的选择,不能够对每个类别或学习难度灵活的微调/偏移。
伪标签质量
预训练的 BLIP 能够缓解在线学习时 CLIP 所受到的误导作用,但是质量准确的上限将会被约束于 BLIP 模型。
如何确保伪标签生成质量的可靠性?
不一定要用预训练模型进行交叉验证,或许有其他的方法增加可靠性。因为一味地依赖学习模型翻新标签,而忽视伪标签的评估,将会造成在高噪声情形下造成严重误导。
通用性
鲁棒性提示学习方向,或许应当走出去。不仅限于 CLIP,更多地面向通用的预训练模型,比如针对文本、图像等都可以进行微调。
感悟
创新
因为算是第一次发表这种研究型文章,在此也感谢方超伟的引领,没有他们仅依赖自己单薄的经验,难以发表到学术会议中。
在这个过程中,一直困惑地是何为创新?比如说我将概率论中的概率分布成功引用到了样本子集的划分当中,这种首次将样本成功划分为三个子集进行处理的应用,已经很让我激动了,因为是当时自己手推的。创新性似乎是在于划分子集的过程,因为一直怀疑这种概率分布划分方法比较简单。
然后启发性,通过其他文章的启发也给了很多帮助,通过借鉴其他论文的做法,适应地改造自己的方法,似乎也是一种创新。
Idea 的产生
这个过程是很随机的,也是一个比较有嚼劲的过程。在这个项目中,从最开始提出稍微不切实际的想法,到后来每周一个新想法,似乎诀窍就是不断地分析、不断地思考,但唯一没有做好的地方是,对想法没有充分地分析可行性和合理性,仅仅是直觉上的合理。
习惯
初步地科研项目带来的最大好处是,迫使你形成良好的习惯,比如以什么形式记录研究日志,以什么形式记录实验结果,项目文档材料怎样组织等等。
还有一个较为重要的地方,就是怎样较好地记录学习过程,因为在这过程中不可避免地要学习很多东西,需要有一个平台/方式来良好地组织学习过的内容,以便后续能够基于此做出新的改进。
研究模式
由果溯因型
在本科的实习期间,也可能是不同老师有不同的培养方式,我们主要是选择一篇最新的文章进行复现,然后想尽各种办法,去提高最后的指标结果。研究问题就是我要超过SOTA,只要能work,就可以发论文。
当经过各种尝试与探索,得到结果还是有部分超过SOTA,就开始做微调(再把结果调一调),再历经各种trick,似乎终于能够把结果调到全部都好,OK现在开始着手想一个问题,分析它为什么起作用了(但实际上是讲好一个故事即可)。
这种研究模式,似乎是最能速成的,但绝不是最好的。
由因溯果型
等到后来,跟师兄们学习讨论后,我也明白了另外一种正确的研究模式,首先针对现有的最新研究方法以及对照自己的研究愿景(预期),分析该方法有没有达到预期,如果各个方面都达到了,那么可以考虑想一些新的研究内容;如果没有达到,那就可以从中分析出问题来,然后逐步细化到一个小方面或多个方面,最终拿到这个研究问题后,开始探索自己的解决方案。
当经过实验验证后,认为自己的解决方案能够改善这个问题,那么这时候就可以发表论文,来向同行们分享告知。
这样的研究模式,不需要刻意地去凑一个故事,而是从实际中出发,真正地解决问题。
Open Talk
在此欢迎大家来讨论,Robust Prompt Learning 这个方向还有许多需要改进的地方,以及结合我发现的一些点,都可以进一步地深究。
Screening, Rectifying, and Re-Screening: A Unified Framework for Tuning Vision-Language Models with Noisy Labels
