[CVPR 2023 CodeTalker] [Lip Sync.] [Context Expression]
CodeTalker: Speech-Driven 3D Facial Animation with Discrete Motion Prior
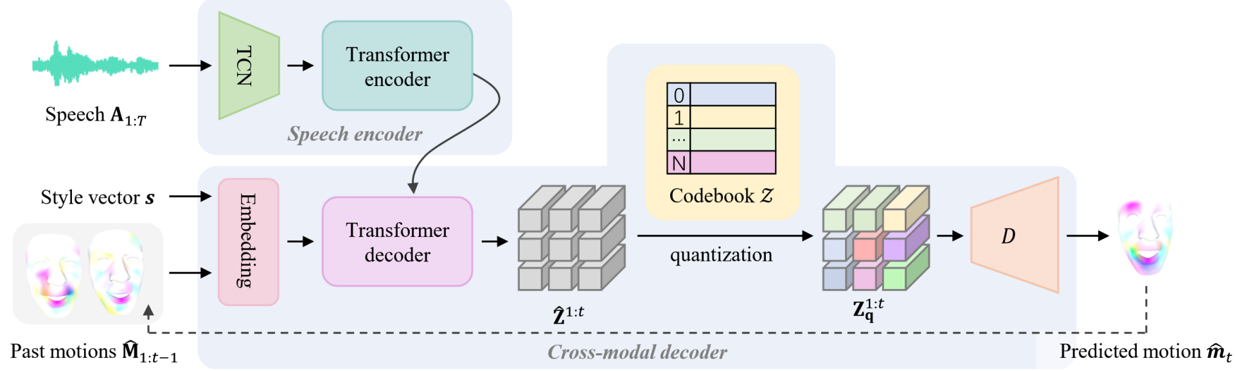
Figure: CodeTalker (CVPR 2023)
Task: Reduce cross-modal mapping uncertainty and regression-to-mean by casting speech-driven animation as a code query task.
Motivation:
By mapping speech to a finite proxy space (discrete codebook), uncertainty is reduced and synthesis quality improves.
Motion: Mesh Vertex Offsets.
Dataset:
Views: Uses VQ-VAE to learn a discrete code space, offering more detailed representations than parameter-based methods.
Problems:
- Diversity: No explicit stochasticity declared; diversity evaluation lacking.
- Controllability: Lacks explicit emotion control; adjusting output requires vertex-level manipulation.
- Style: Stores stylized motion priors in a codebook — storing expressive priors remains under-explored.
[ICCV 2025 GaussianSpeech] [Lip Sync.] [Context Expression]
GaussianSpeech: Audio-Driven Gaussian Avatars

Figure: GaussianSpeech (ICCV 2025)
Task: Decomposes lip and wrinkle features from audio to animate the FLAME mesh; rendering via 3D Gaussian Splatting.
Motivation: Real-time, free-viewpoint, photorealistic 3D-consistent facial synthesis.
Motion: Mesh Vertex Offsets.
Dataset: Multi-View Audio-Visual Dataset
Views: Uses 3D Gaussian fields + dynamic deformation for lip-sync realism and flexibility in avatars.
[IJCAI 2025 GLDiTalker] [Lip Sync.] [Context Expression]
Speech-Driven 3D Facial Animation with Graph Latent Diffusion Transformer

Figure: GLDiTalker (IJCAI 2025)
Task: Improve lip-sync via graph-based encoder & codebook; enhance diversity using latent diffusion.
Motivation: Address modality inconsistencies and misalignment.
Motion: Mesh Vertex Offsets.
Dataset:
Views: Uses facial meshes and a graph-latent-diffusion transformer to enable temporally stable 3D facial animation.