[SIGGRAPH 2024 DiffPoseTalk] [Lip Sync.] [Context Expression] [Dataset Collection]
DiffPoseTalk: Speech-Driven Stylistic 3D Facial Animation and Head Pose Generation via Diffusion Models
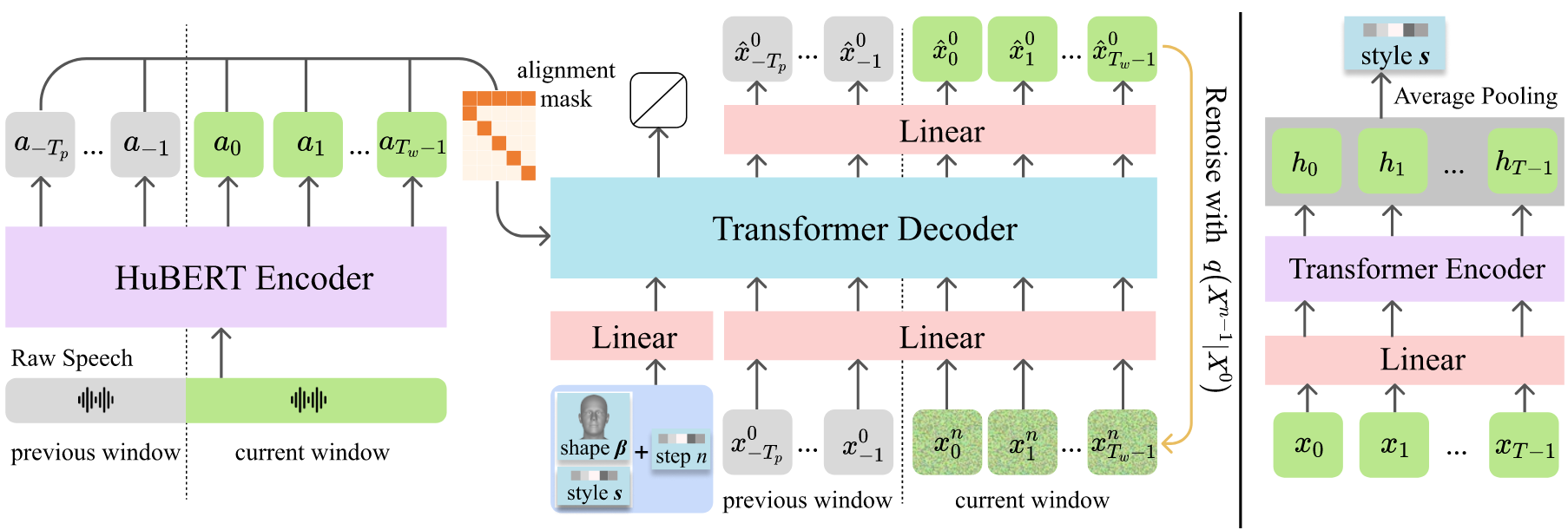
Figure: DiffPoseTalk (SIGGRAPH 2024)
任务 (Task): 增强 stylistic 的 3D 人脸驱动。现有方法或者采用确定性回归方式学习 speech-to-motion 的映射,或者仅使用 one-hot 编码实现 stylized animation,均无法有效捕获 style 的复杂性,限制了泛化能力。
动机 (Motivation): 从一个短参考视频中提取 style 嵌入向量来表示个性化风格,结合扩散模型实现高质量、风格多样的驱动合成。
运动类型 (Motion): Expression and pose parameters.
数据集 (Dataset): 在 TFHQ 数据基础上收集 VFHQ 数据作为扩充。
方法观点 (Views):
- 在单帧驱动参数上进行扩散生成;
- 引入 style 嵌入向量表示多样的说话风格。