Motion-based Literature Structure
基于运动表征的文献组织分类方法,主要从音频驱动肖像生成的现有方法进行分类,将文献按照不同运动表征方式分为基于顶点的(Vertex-based)和基于参数的(Parameter-based)两大类。
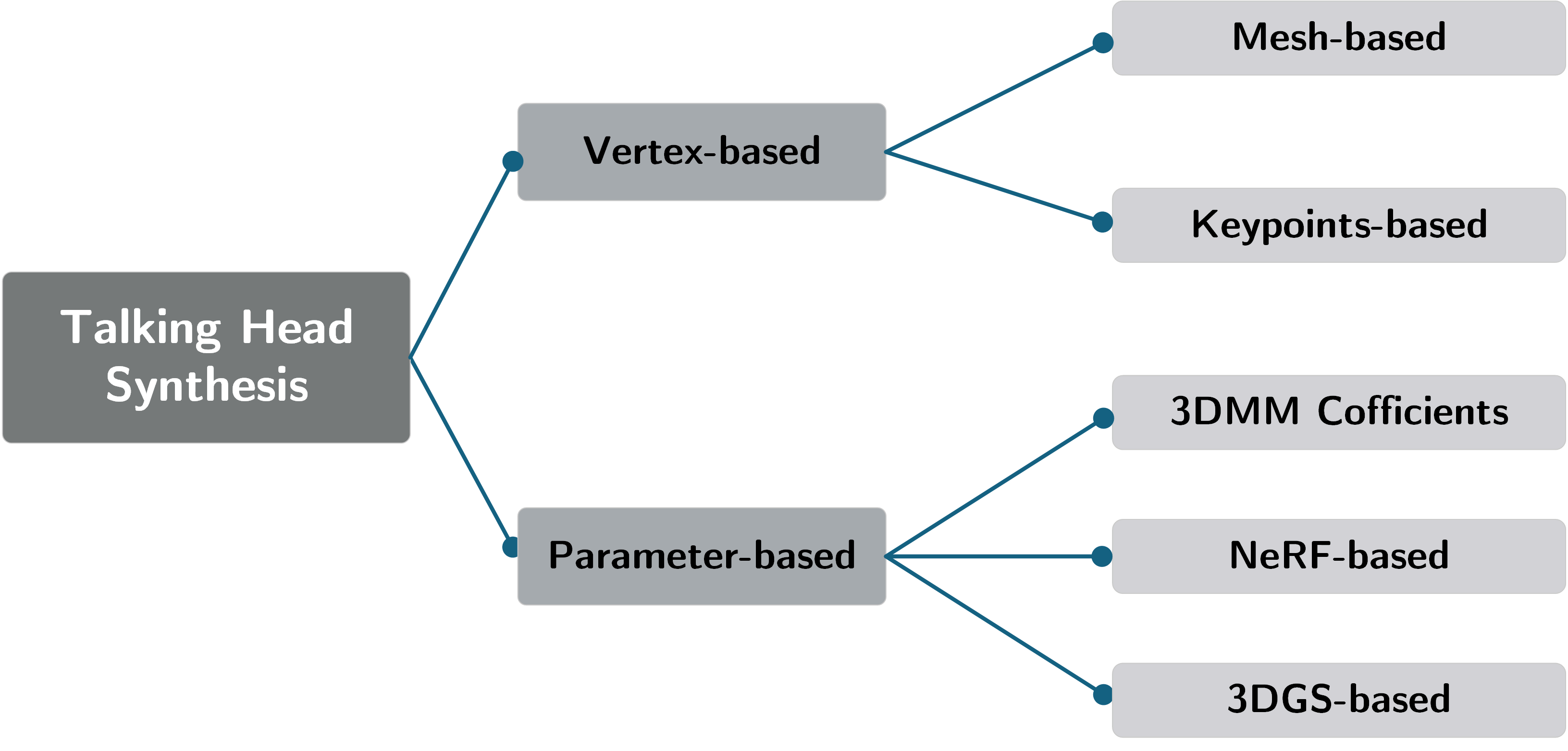
Vertex-based
基于顶点的方法主要包括 Mesh、Keypoints 类别,通过直接从音频特征预测顶点位置或基于标准模板的顶点偏移量来实现运动的生成。
Mesh-based
基于网格的表示方法通过顶点 (Vertex) 和面片 (Face) 构建数字人脸拓扑,实现精细形变控制。
局部区域的精细控制
相比于Blendshape类方法,能够通过预测顶点坐标,细化口型内部区域,实现精细粒度的运动控制。
直观的运动表示
通过显式几何表征人脸,易于构建顶点位移直接表示区域的运动特征,便于头部的运动生成。
Keypoints-based
关键点表示通过稀疏的关键点来描述面部动作,并构建轻量级的驱动框架。
轻量驱动控制
面向实时应用,计算量小,驱动效率高。
难以精细控制
基于关键点的方法难以捕获微妙的面部运动,包括眼睛以及睫毛运动。
隐式关键点灵活性
提取隐式关键点作为人脸表征,不依赖固定的3DMM顶点位置,维持效率的同时增加了驱动的灵活性。
Parameter-based
基于参数的方法主要利用隐式的表征参数,进一步按照预定的规则进一步地合成参数化人脸。常用的表征方法包括,3DMM系数、NeRF隐式神经表征、3DGS显式表征方法,通过预测各个表征参数以及参数的变化量生成人脸运动。
3DMM Coefficients
3DMM通过线性基向量组合构建参数化人脸模型,已成为学术研究中的主流范式。
形状混合稳定性
通过参数化人脸驱动的方式,能够弱化中间系数预测损失更具稳定性。
显式参数可控性
易于解耦出头部姿势与表情系数表征人脸,能够提高对人脸驱动的可控性并易于接受用户控制信号进行调控。
提供宏观整体结构
基于混合形状的3DMM能够为驱动人脸提供很好的宏观结构,增强了全局表情的驱动生成。
NeRF-based
NeRF通过体积渲染构建稠密的辐射场表示,实现高质量人脸重建与合成,但渲染速度较慢,难以满足实时驱动需求。
较长的训练和推理时间
需要数个小时完成一个角色的训练,并且推理时间缓慢,难以泛化到其他人物。
可控性差
由于统一的隐式神经表示,难以接受多条件输入控制生成驱动视频;不能够显式地控制人脸表情、姿势,可能会造成不自然的结果。
复杂的网络结构
需要隐式地学习庞大的MLP编码器,会进一步地限制收敛性和重建质量。
3DGS-based
3D高斯点云通过各向异性高斯建模,实现了高质量实时渲染,通过引导高斯点分布实现人脸驱动。
高效驱动能力
基于3DGS表征人脸,能够实现高效地人脸驱动,并借助渲染能力实现实时驱动,网络简单,计算高效。
泛化性弱
借助高斯点的属性偏移实现驱动,依赖于人物的特定数据,难以实现跨人物之间的驱动。
Problem-based Literature Structure
在统一的研究问题下,不同的研究工作侧重于解决统一研究问题的不同方面,因此需要对所有文献按照不同研究问题进行细化分类。
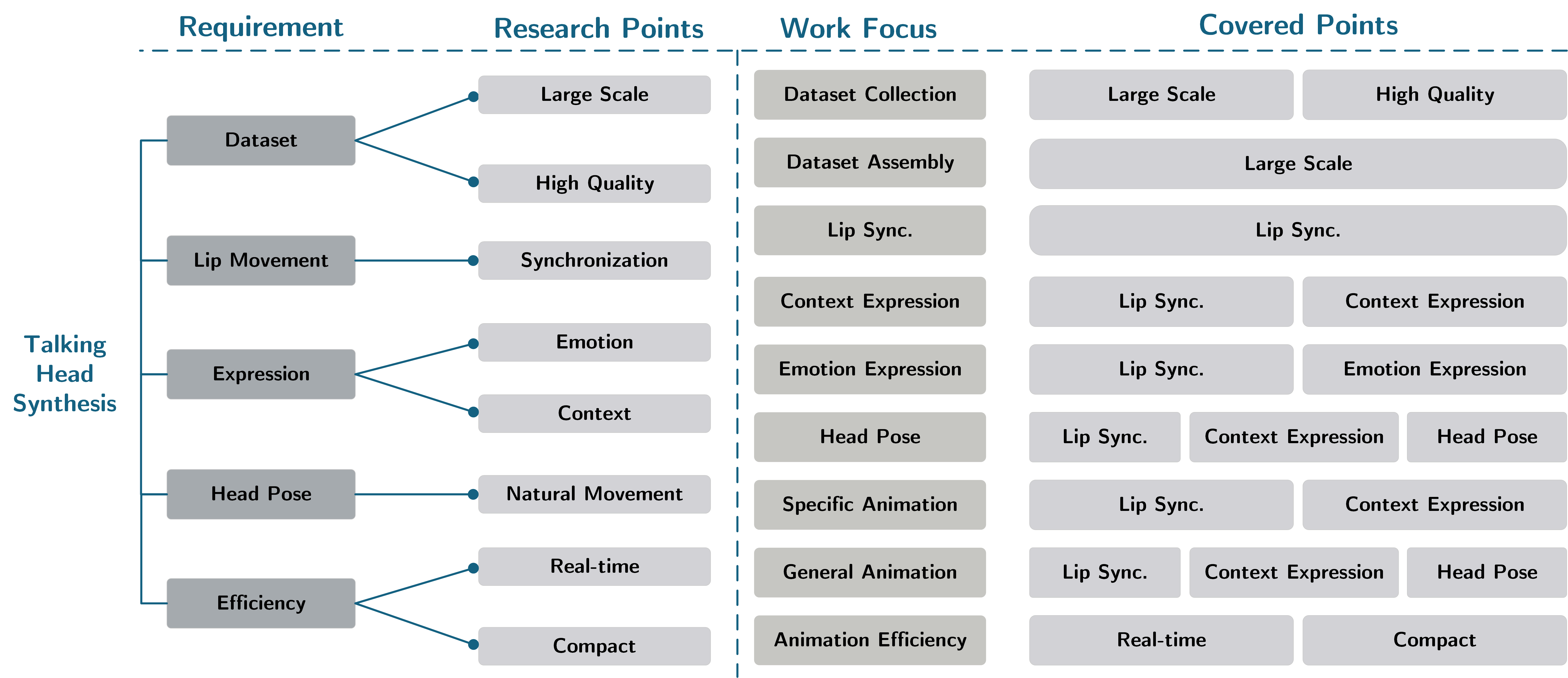
如图所示,将 Talking Head Synthesis 研究分为五个需求,分别是训练数据、口型同步、表情生成、头部姿势以及驱动效率。
对于不同的需求,分为更细化的研究目标,例如对数据集的要求需要是大规模、高质量数据,现有数据集有些虽然规模庞大,但是质量不高,相反质量较高的数据集,数量反而较少,这就造成了现有研究的矛盾;
- 口型同步 主要是对于音频和口型实现准确性与同步性,口型应当准确地对应当前音频要素的内容,并且能够与音频保持同步性;
- 表情生成 分为情感驱动和语境驱动两种方式,不同的驱动方式具有独特的影响;
- 头部姿势 是个性化风格,需要从大量数据中学习出多样的风格,需要尽可能地自然;
- 驱动效率 是实现模型紧凑型以及实时驱动的要求,一般模型参数量少、结构简单,便可以实现较高的驱动效率。
不同的工作,关注点不同,从数据集构造到实现高效驱动,涉及了不同的研究目标。
Model-based Literature Structure
Regressive Models
精确度高
直接学习最终的驱动结果,可控性高。
回归均值问题
对于相同的音素会对应多种合理的表情变化,这种一对多的模糊性会造成回归模型过度产生过度平滑的人脸运动。
泛化性弱
现有回归方法都是身份依赖型的,在零样本推理中表现出不自然的结果,一些方法需要额外引入适应网络进行个性化匹配。
Generative Models
Strengths
生成多样化
生成模型直接学习条件概率分布,建模潜在的数据分布,确保了多样的样本生成。
高保真驱动细节
生成模型例如扩散模型能够捕获复杂的数据分布,隐式地记忆细微的个性化细节。
跨模态对齐
生成模型尤其是Transformer结构能够将不同模态的特征进行高效融合,有效地建模音频复杂的解耦特征与运动序列之间的对应关系。
Shortcomings
跨模态映射的不确定性
生成模型能够产生多样的数据样本,但是多样的数据分布导致驱动不稳定性。
多样且大规模数据需求
生成模型的训练需要大规模的数据集学习潜在的数据分布。
训练和推理缓慢
大规模生成模型面临着庞大的参数学习任务,需要大量的计算资源进行训练以及表现出缓慢的推理速度。